
Delivered Megawatts: The Ultimate Colocation Buying Guide for the AI Era
Why AI colocation is no longer a rack-leasing business and what operators, buyers, sellers, and investors need to do now.

Is this market constrained, or just misunderstood? Everyone keeps quoting megawatts, but nobody agrees on what they actually mean. A “20 MW site” can mean land with a utility conversation, power at the property line, a future substation, powered shell, or a commissioned facility that can take AI servers and keep them running. Those are not the same product. The market is not short on announcements. It is short on server-ready power: substations, transformers, switchgear, UPS, generators, cooling, network, controls, permits, commissioning, and a buyer that can actually be underwritten.
That is why oversupply, undersupply, cancellations, and price spikes can all be true at once. They are talking about different kinds of megawatts. The next decade will not be won by the firms with the most land. It will be won by the firms with the highest probability of delivered megawatts. Capacity is no longer just sold. It is allocated.
First, we get back to first principles: what a data center actually is. Then we explain why AI breaks the old colocation model. Then we separate fake capacity from real capacity. Then we look at the bottlenecks that actually matter: electrical architecture, cooling, power procurement, credit, tariffs, local politics, and behind-the-meter generation. Finally, we lay out what operators, buyers, and investors should do now. The old question was: how much space can I lease? The new question is: how many AI megawatts can I actually operate, by what date, under what power architecture, with what cooling design, in what jurisdiction, with what credit support?
Check out the FPX Colocation Marketplace → marketplace.fpx.world/colocation
Where we allocate the only thing that matters: megawatts that can actually run your workload.1. A data center cannot just be treated like a real estate project
A data center is not real estate. It is a tightly coupled machine that converts electricity into compute and heat, and the only question that matters is whether that machine works under load and under failure. The building is just a shell. The product is the system inside it.
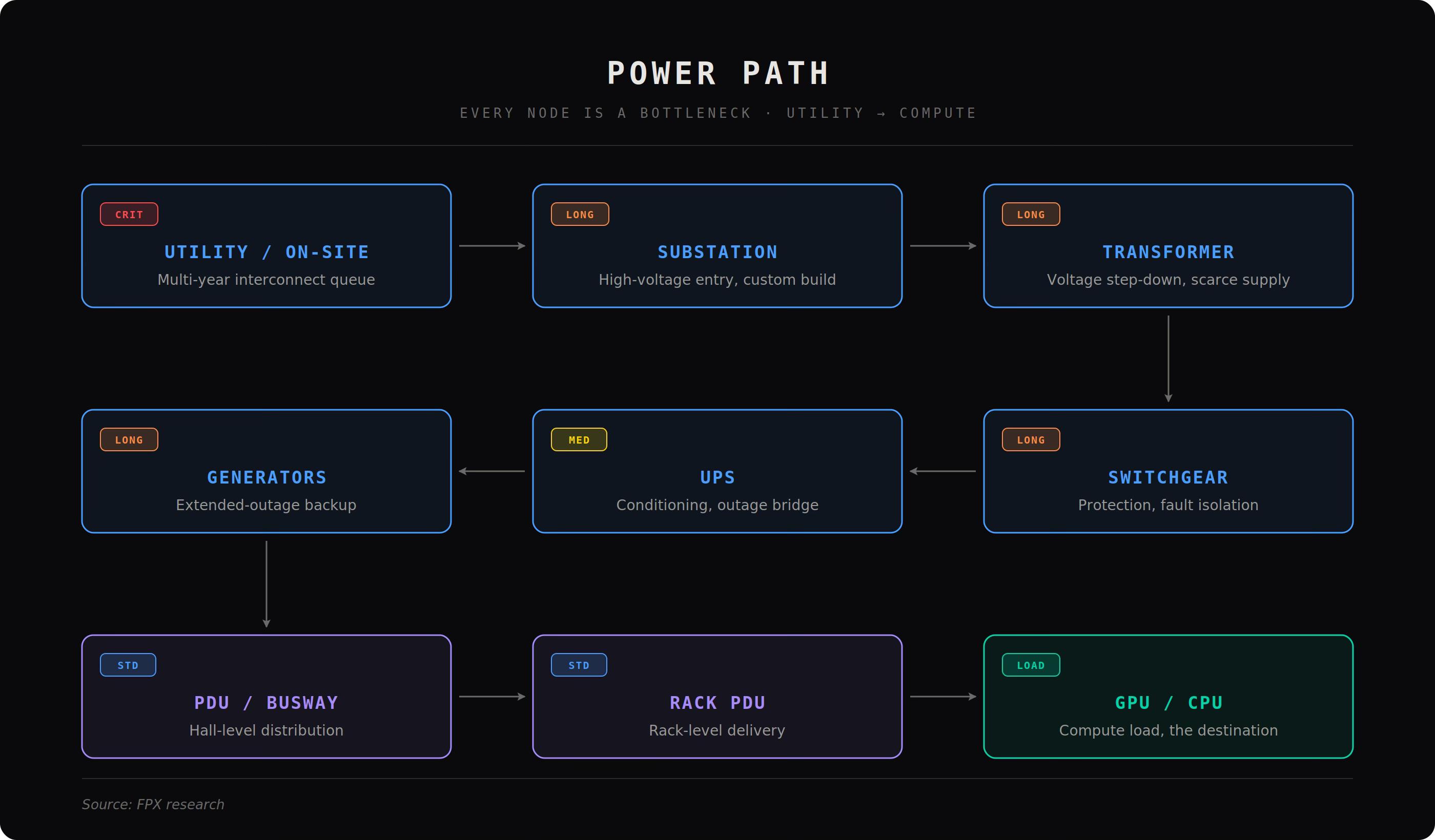
Start with the power path, because if this breaks, nothing else matters. Power enters at the utility interconnection or onsite generation. It flows into the substation (the electrical front door that receives high voltage power and steps it down). Then into transformers (devices that convert voltage levels; if these are not secured, the project is not real). Then into switchgear (the protection and control layer that isolates faults and routes power safely). Then into the UPS (Uninterruptible Power Supply), which stabilizes power and bridges outages. Then into generators or backup systems that carry load during extended failures. From there, power is distributed via PDUs (Power Distribution Units), RPPs (Remote Power Panels), and busway (overhead power rails) into the rack, where rack PDUs and power shelves finally feed GPUs and CPUs. Every step has lead times, failure modes, and constraints. If a seller cannot walk this chain cleanly, they do not have capacity.
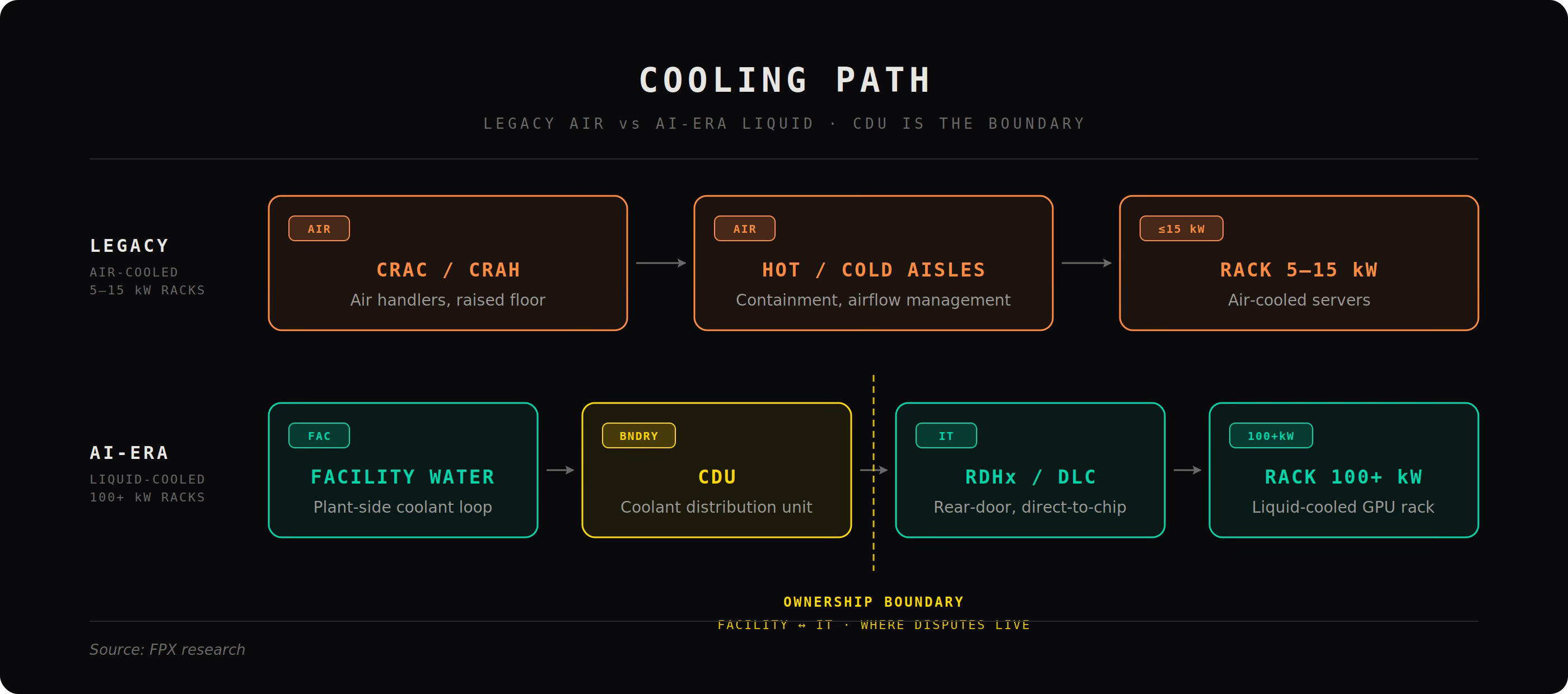
Now mirror that with the cooling path, because every watt of compute becomes a watt of heat. Legacy systems used CRACs and CRAHs (air cooling units), which worked at low densities. AI breaks this. At high density, you move to rear door heat exchangers (cooling at the back of the rack) and direct to chip liquid cooling (coolant flowing directly over processors). The core device here is the CDU (Coolant Distribution Unit), which regulates flow, pressure, and temperature between facility water and IT cooling loops. If the site cannot specify temperatures, flow rates, CDU ownership, and failover behavior, it cannot support AI workloads. Cooling is no longer a feature. It is industrial thermal infrastructure.
Then come the other systems most people ignore until they fail. The network layer includes carrier fiber, cloud on ramps, and internal high speed switching fabric that determines latency and throughput. The control layer includes BMS (Building Management System) and EPMS (Electrical Power Monitoring System), which monitor and automate the plant. The life safety layer includes fire suppression, security, and operational procedures that keep the facility insurable and operational. These are not add ons. They are part of the machine.
The key is that all of these systems must work together under stress. Redundancy is often misunderstood. “A plus B” power means nothing if one side cannot actually carry the full load during failure. “Tier III” means nothing if you cannot see the one line diagram and the failover case. Commissioning proof matters more than marketing labels.
This is why AI changes everything. Legacy colocation could survive on vagueness because a 5 to 15 kW rack gave margin for error. AI removes that margin. Today’s racks are already around 100 to 150 kW and moving higher, which turns the data center into an industrial system, not a flexible office environment. At these densities, power quality, thermal stability, protection systems, and failure handling are no longer secondary. They are the entire product.
If you are buying AI capacity, you are not buying racks or space. You are buying a machine that must deliver power cleanly, remove heat precisely, operate continuously, and survive failure conditions. If the operator cannot explain exactly
2. Delivered megawatts are the new currency
The market keeps quoting megawatts like they are interchangeable.
They are not.
Most of what gets called “capacity” today is noise. Press releases, land options, utility conversations, tax incentives, future substations. None of that runs a single GPU. The gap between what is announced and what is actually usable is where deals break, timelines slip, and buyers get burned.
There are only four types of megawatts in this market:
Announced: marketing. Looks big. Means nothing.
Optioned: land and early utility positioning. Still nothing you can deploy on.
Committed: real work has started, studies, permits, some equipment strategy, maybe a tenant. Still not usable.
Delivered: energized, cooled, commissioned, contracted, and able to take servers now.
Only the last one matters.
Everything else is pipeline risk.
AI buyers do not need optionality. They need megawatts that can actually take racks, at density, on time. Investors should not underwrite how many megawatts exist on paper. They should underwrite the probability that those megawatts make it through power, equipment, cooling, permitting, and credit into something real. Operators who blur that line are going to get exposed fast.
This is where the market splits. The top tier controls substations, transformers, switchgear, cooling systems, and procurement pipelines. They know where their equipment is coming from, when it lands, and how it gets commissioned. The bottom tier controls land, decks, and excuses. That bottom tier is about to get wiped out.
The phrase “AI-ready” is already collapsing. It will only mean two things going forward: either the operator can prove the site supports the actual rack density, cooling method, electrical architecture, and failover condition on a real timeline, or they cannot. There is no middle ground.
A rendering is not a megawatt.
A utility conversation is not a megawatt.
A tax incentive is not a megawatt.
A future substation is not a megawatt.
A delivered megawatt is a megawatt.
And here is the part most people are still missing: even “delivered” is not enough if it is designed for the wrong future.
The industry keeps framing AI colocation as a cooling problem. That is outdated. The next bottleneck is electrical architecture. Today’s racks are already pushing past 100 kW and heading toward 300 kW and beyond. At megawatt scale, the legacy 54 VDC architecture breaks. The physics are not negotiable. At 1 MW, you are dealing with roughly 18.5 kA of current at 54 VDC versus about 1.25 kA at 800 VDC. Same rack, completely different system behavior.
That is why the shift to higher voltage distribution is not optional. It is the only scalable path. Without it, you end up stuffing racks with power shelves, copper, and complexity just to keep the system alive. That does not scale economically or physically. The next generation of real capacity will be built around centralized conversion and high voltage distribution, not incremental patches on legacy designs.
Cooling is scaling in parallel. At megawatt levels, heat rejection becomes a fluid dynamics problem, not a facilities checkbox. You are talking about massive flow rates, CDU scaling, and thermal systems that behave more like industrial plants than data halls. At the same time, protection becomes critical. Higher density means higher fault energy, higher arc flash risk, and tighter operating margins. One failure can take out entire rows of equipment.
This is why most “capacity” today is mispriced. It is being valued as if it can support the next generation of hardware when it cannot. A site designed for current density without a path to future electrical architecture is already partially obsolete.
FPX view: the market is not just filtering fake megawatts from real ones. It is about to filter current-ready megawatts from future-proof megawatts. The winners will not be the ones who can announce capacity. They will be the ones who can deliver it at the densities the next hardware cycle demands, safely, efficiently, and on time.
3. The “50% canceled” headline is the wrong fight
The market is now arguing about whether half of U.S. data center capacity is being delayed or canceled.
That is the wrong argument.
The market is not canceling half of AI data center capacity.
It is canceling the illusion that every announced megawatt was real.
Yes, projects are being delayed. Some are being killed. Tax incentives are being pulled back. Local politics are getting harder. Utility tariffs are tightening. Power equipment is still constrained. And in FPX’s Marketplace, U.S. sites have risen roughly 15% on average.
But that is not a demand-collapse story.
It is a sorting cycle.
The weak pipeline is getting exposed: land-banked campuses, speculative press-release megawatts, undercapitalized developers, sites without a real power path, and buyers without the credit to secure capacity.
The real pipeline is not disappearing. It is being repriced, delayed, preleased, or allocated to stronger buyers.
That is the part the headline misses. In this market, capacity does not simply go to whoever wants it. It goes to whoever can make the provider, utility, lender, and operator believe the load is real.
That favors hyperscalers and large enterprises.
It hurts neoclouds, smaller enterprises, and speculative AI infrastructure buyers.
They may have demand. They may even be willing to pay. But if they cannot support the credit package, infrastructure commitment, ramp schedule, and utilization story, they get pushed out.
So yes, more projects will be canceled.
But no, half of real AI capacity is not going away.
The better read is this:
Announced capacity is getting cut. Bankable capacity is getting scarce.
That is why waiting for the “shakeout” is dangerous. More supply should arrive into 2027, but the best of it will not show up as clean, open inventory. It will already be spoken for, repriced, or reserved for buyers with stronger credit and earlier commitments.
FPX view: the market is not oversupplied. It is finally learning the difference between a rendering and a delivered megawatt.
4. The next bottleneck is electrical architecture
The industry keeps saying AI colocation is a cooling problem.
That is outdated.
Cooling matters, but cooling is no longer the limiting factor. The real constraint now is electrical architecture, and most of the market is not prepared for what that actually means.
AI racks are scaling faster than the infrastructure underneath them. A 100 kW rack is already a different system. A 300 kW rack is not an extension, it is a break. A 1 MW rack does not fit inside legacy assumptions at all. At that level, you are not just delivering power, you are managing current at a scale that makes traditional designs inefficient, expensive, and in some cases physically impractical.
This is where physics shows up.
At low voltage, current explodes. A megawatt rack at legacy voltage levels implies massive current, massive copper, massive losses, and massive heat inside the power delivery system itself. That is why the industry has been stuffing racks with power shelves, busbar, and workarounds. But that approach does not scale. It gets heavier, hotter, more complex, and more failure-prone with every step up in density.
The only real solution is to change the architecture.
Higher voltage distribution fixes the problem at the root. Increase voltage, current drops. When current drops, everything else gets easier. Less copper. Lower losses. Less heat. Cleaner routing. More scalable delivery. That is why the shift toward high voltage distribution is inevitable, not optional. This is not a design preference. It is a constraint imposed by physics.
And this is where most “AI-ready” capacity breaks.
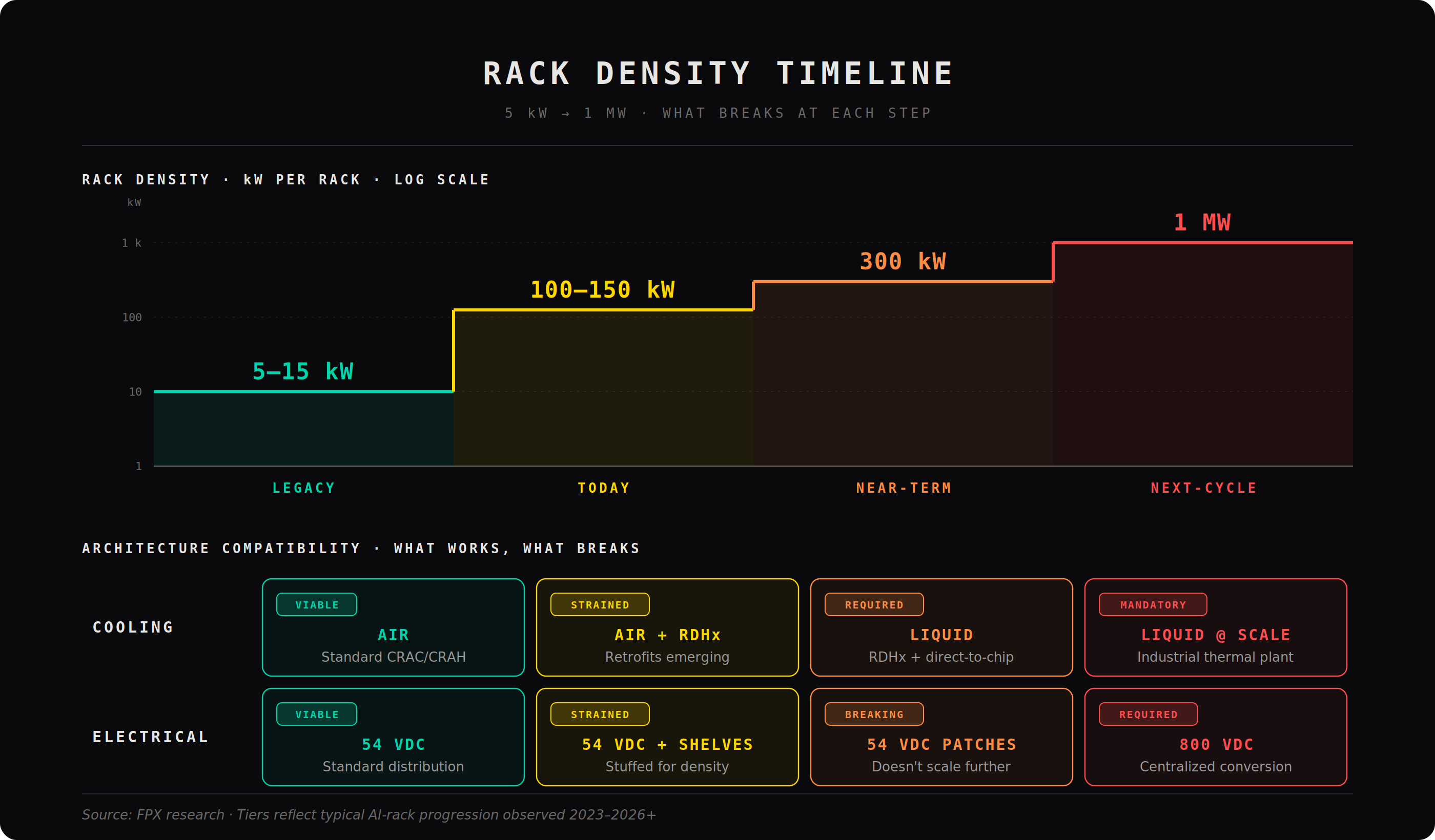
A facility designed around today’s rack density without a clear path to higher voltage distribution is already capped. It may run current deployments. It may look fine on a spec sheet. But it will struggle or fail to support the next generation of hardware without major rework. That is not a theoretical risk. That is already in the design cycle.
At the same time, cooling is scaling into an industrial problem. At megawatt density, heat rejection is no longer about airflow optimization. It is about fluid systems operating at high flow rates, high pressure, and tight tolerances. CDU capacity, facility water loops, and heat rejection systems start to look like process engineering, not facility management. And as density rises, protection becomes critical. Higher power means higher fault energy. Arc flash risk increases. A single failure event can destroy entire rows of equipment. This is not just harder engineering. It is a different risk profile.
Now layer in the part the market is still getting wrong.
AI colocation is not one business. It is splitting into two.
Training and inference are diverging, and that divergence directly impacts how electrical and thermal infrastructure should be built.
Training is power first. It wants the largest, densest, most expandable megawatt blocks available. It will move to where power exists, even if that means remote campuses, hybrid grid and onsite generation, and massive internal power and cooling plants. Electrical architecture is the core constraint here. If the site cannot scale power delivery efficiently, it is not a serious training site.
Inference is latency first. It wants proximity to users, dense fiber, cloud adjacency, and predictable network performance. It is distributed, regional, and network-constrained rather than purely power-constrained. But it still requires high density and often liquid cooling. The difference is not air versus liquid. The difference is economics and placement.
Same AI umbrella. Completely different infrastructure problem.
This is where the market is about to make a major mistake.
It is still underwriting sites as if one “AI-ready” design can serve both. It cannot. Training sites need power architecture that scales into megawatt racks, centralized conversion, and massive thermal systems. Inference sites need network-dense metros with enough power density to run efficiently, but optimized for latency and distribution.
If you use the same framework for both, you are not doing analysis. You are doing marketing.
This is the real implication of the electrical bottleneck.
It is not just about voltage levels or copper. It is about whether a site can evolve with the hardware and whether it is even built for the right workload category.
Operators need to design for the next two hardware cycles, not just the current tenant. Buyers need to ask whether the site can migrate into future power architectures without breaking. Investors need to stop underwriting demand in aggregate and start underwriting whether specific assets can stay relevant as density increases.
Most sites cannot.
That is the gap.
And that gap is where the next generation of winners will come from.
6. AI colocation is splitting into two different markets
The phrase “AI data center” is becoming too lazy to be useful.
Training and inference are not the same business. They do not want the same sites, the same power profile, the same cooling design, the same network, or the same underwriting model. Treating them as one category is how buyers pick the wrong site, operators build the wrong product, and investors misprice the asset.

Training is the brutal one. It is power first, density first, liquid cooled, campus scale infrastructure. Training wants huge contiguous megawatt blocks, cheap and expandable energy, deep internal networking, high voltage power delivery, massive thermal plants, and a site that can absorb future rack densities without falling apart. It is less sensitive to being close to the end user. If the power is real, the fiber is good enough, the operator is credible, and the county will allow it, training can move.
Inference is different. Inference is not one thing either. Even inside inference, the workload is splitting between prefill and decode. Prefill is the front end of the model response: processing the prompt, context, documents, tools, and memory. It is compute heavy and can often tolerate more distance. Decode is the token generation loop: the sequential output users actually wait on. It is latency sensitive, concurrency sensitive, and tied much more directly to user experience. That means inference infrastructure will fragment. Some of it will look like smaller training style clusters. Some of it will live in regional metros. Some of it will be optimized around fiber depth, cloud adjacency, jitter, and fast deployment rather than maximum campus scale.
That is the real estate implication. Training sites look like industrial power projects. Inference sites look like distributed digital infrastructure. Training is about delivered megawatts in one place. Inference is about putting enough compute in the right places.
Cooling is not a standalone category anymore. It is a function of workload type. Serious training workloads are moving toward dense liquid cooled environments because the rack densities force it, but “liquid cooled” is already becoming as vague as “AI ready.” It can mean rear door heat exchangers, direct to chip cooling, facility water to the hall but not the rack, customer owned CDUs, operator owned CDUs, or no clear ownership at all. The question is not whether the site is “liquid ready.” The question is whether it can support the exact cooling topology required by the hardware: supply and return temperatures, flow rates, pressure, CDU capacity, coolant quality, maintenance responsibility, leak response, commissioning schedule, and the failover condition. A plus B is not redundancy if either side cannot carry the load when the other side fails.
This is where a lot of AI colo disappointment will show up. Buyers will sign for “liquid cooled capacity” and later discover that the facility water loop, CDU boundary, thermal envelope, or operating liability does not support the deployment they thought they bought. The next generation of disputes will not be about square footage. It will be about cooling scope, rack density, delay liability, and who is responsible when the system fails commissioning. For training, cooling is industrial thermal infrastructure. For inference, the picture is more fragmented: some deployments will use lighter liquid cooling, some will adapt to air cooled or hybrid environments, and some inference specific accelerators will make existing colo more usable. Either way, the cooling design has to match the workload, not the marketing deck.
Inference will be more disruptive because it has to fit into the real world faster. Not every inference deployment can wait for a custom 100 MW campus. A lot of it will need to adapt to available colo, metro locations, air cooled or lighter liquid cooled designs, and inference specific accelerators that are built to improve performance per watt, latency, and deployment flexibility. Groq style architectures, decode optimized chips, and other inference specific systems matter because they change the site selection problem. They make more existing colo usable. They make smaller footprints more valuable. They turn inference into a speed and placement game, not just a raw megawatt game.
That is the market split.
For training, you are often betting on future projects. If you need a 50 MW, 100 MW, or 110 MW plus campus, you are not really buying today’s inventory. You are underwriting development risk. You are betting on the operator, the utility, the equipment queue, the interconnection timeline, the cooling design, the generator strategy, the financing, the county, the tariff, the permits, and the local politics. The lease is only one piece of the risk.
For inference, the opportunity is different. The winners will be the operators who can turn existing or near term capacity into deployable inference capacity quickly. That means enough density, good network, clean operations, credible power, and a design that matches the actual workload instead of pretending every AI deployment needs the same industrial campus.
This is the next major underwriting mistake in the market: using one “AI ready” framework for everything.
Training wants power scale.
Inference wants placement.
Training wants dense liquid cooled campuses.
Inference wants latency, availability, and hardware flexibility.
Training is a future project bet.
Inference is a deployment speed bet.
Both are valuable. They are just not the same asset.
FPX view: the market is going to stop valuing “AI capacity” as one generic category. It will split between training capacity and inference capacity, and the diligence will look completely different. If a seller says a site can do both, the next question is simple: for which hardware, at what density, under what cooling design, with what network profile, by what date?
If they cannot answer that, they are not selling AI capacity.
They are selling a slogan.
7. The county matters as much as the cabinet
This is where the committing to larger sites especially for training workloads gets dangerous.
If you are taking 2 MW of inference capacity in an existing facility, you are diligencing an operating asset. If you are taking 10 MW, 50 MW, or 100 MW plus for training, you are often underwriting a project that does not fully exist yet. That means you are not just betting on power and cooling. You are betting on the operator, the utility, the permitting path, the substation schedule, the equipment queue, the financing, the tariff, the water strategy, the generator plan, and the county.
The county is not background noise.
The county is part of the capacity stack.
For years, data center site selection was mostly a power, fiber, land, tax, and latency exercise. Find cheap power. Find enough land. Find fiber. Get incentives. Build. That world is gone. AI campuses are too large, too visible, too power hungry, and too politically sensitive to slip quietly through local approval.
A 100 MW campus is not a real estate project to the community. It is a power project. It is a water project. It is a noise project. It is a tax project. It is a road project. It is a diesel generator project. It is a transmission project. It is a question every resident understands: what do we give up, what do we get back, and who pays when the grid needs upgrading?
That is why the best site on paper can still die in county politics.
A cheap site in a hostile county is not cheap.
A fast utility path in a county that will fight every permit is not fast.
A tax incentive that becomes a political target is not bankable.
A power allocation that depends on ratepayers absorbing grid costs is not secure.
A project that has not explained noise, water, generators, transmission, jobs, and local benefit is not de-risked. It is exposed.
This matters most for larger training workloads because those buyers are often committing before the site is fully delivered. The bigger the block, the more you are buying future execution rather than present inventory. At 10 MW, you can sometimes still find capacity inside a known operating environment. At 50 MW, you are usually into expansion risk. At 100 MW plus, you are underwriting a development thesis.
That changes the diligence.
You are no longer asking, “Does this provider have a hall?”
You are asking, “Will this entire project come into existence?”
That means the county has to be evaluated like a counterparty. Not formally, but practically. Is the local government supportive? Have similar projects been approved? Are residents already organizing against data centers? Is water politically sensitive? Are diesel generators controversial? Are there noise setbacks? Is the tax abatement vulnerable? Will transmission upgrades trigger opposition? Are utility bills rising? Does the project create enough local benefit to survive scrutiny?
Most buyers do not ask these questions early enough.
They ask after the deal is signed.
That is too late.
For operators, the lesson is simple: community strategy is now development strategy. You cannot treat it as PR. Noise modeling, water sourcing, generator permitting, visual screening, road impact, emergency response, grid cost allocation, tax contribution, and permanent local benefit need to be built into the project before the opposition forms. Once the local narrative becomes “data center extracts power and gives nothing back,” the project is already wounded.
For buyers, the lesson is even sharper: do not confuse a provider’s confidence with project certainty. Every developer is confident before a permit hearing. You need evidence. Show me the zoning path. Show me the county record. Show me the utility position. Show me the generator permitting plan. Show me the water plan. Show me the community engagement. Show me what happens if the incentive changes. Show me the delay remedies if local approval slips.
For investors, this is now core underwriting. A county that welcomes the project deserves a lower risk premium. A county that is politically fragile deserves a higher one. A project with secured local alignment is worth more than a project with better land economics and a weaker approval path.
The market keeps acting like the hardest part is finding the megawatts.
That is only half true.
The harder part is making sure the megawatts survive contact with the real world.
FPX view: for large training deployments, the county matters more than the cabinet because the cabinet is replaceable and the county is not. A rack vendor can slip and recover. A transformer can be resequenced. A cooling design can be modified. But if the county turns against the project, your 100 MW commitment can become a press release, a lawsuit, or a two year delay.
At small scale, you buy capacity.
At large scale, you underwrite permission.
8. Water is both over-politicized and under-analyzed
Water is now one of the easiest ways to kill a data center project politically, and one of the easiest issues to misunderstand. The headlines sound terrifying because raw gallon numbers are large. But large numbers without context do not tell you whether a site is reckless, efficient, reusable, dry cooled, wet cooled, drawing potable water, using reclaimed wastewater, operating in a water rich region, or building in a constrained basin.
That is the point SemiAnalysis made with the xAI Colossus 2 comparison. Its estimate put the campus at roughly 346 million gallons of blue water per year versus roughly 147 million gallons for an average In N Out store. Whether you like the framing or not, the lesson is useful: water numbers are easy to weaponize when nobody explains what they mean.
The real question is not, “does the data center use water?” Of course it does. The real question is: what water, from where, under what cooling design, in what climate, with what reuse strategy, and with what local impact?
A dry cooled site is not the same as an evaporative cooled site.
A site using reclaimed wastewater is not the same as a site pulling potable water.
A site in a water rich region is not the same as a site in a stressed basin.
A low density enterprise facility is not the same as a dense AI training campus.
A cooling design built for inference is not the same as one built for training.
This is where operators lose the room. They either dismiss water concerns as emotional, or they show up with engineering language nobody in the county meeting understands. Both are mistakes. Once “data center water use” becomes the headline, the project is already on defense.
The operators that win will make water boring early. They will explain the source, the expected use, the consumptive portion, the cooling method, the seasonal profile, the reuse plan, and the local tradeoff before opponents define it for them. They will show why the scary headline number is not the full story, but they will not pretend the issue is fake.
FPX view: water is often over politicized, but it is not fake risk. The best operators will not be the ones who use the least water in every case. They will be the ones who can design intelligently, quantify clearly, use better sources, communicate with constituents, and earn enough trust that water does not become the reason the project dies. A permit is not permission. Local trust is part of the capacity stack.
9. Incentives, tariffs, and utilities are part of the site
Tax incentives helped build the U.S. data center map. Now they are becoming less reliable.
The old bargain was simple: bring a large capital project, get tax relief, create some jobs, expand the local tax base, and everyone moves on. AI changes that bargain. A 100 MW data center is not a quiet commercial project. It is a visible load on the grid, a political issue, and in some counties, a ratepayer fight waiting to happen.
The question local governments are asking is blunt: if a data center takes huge power, receives tax breaks, creates relatively few permanent jobs, and requires grid upgrades, what exactly does the community get back?
That question is not going away.
Some incentives will survive. Some will be rewritten. Some will come with energy efficiency rules, job requirements, local investment commitments, grid cost protections, or clawbacks. Some will disappear completely. NCSL says 38 states currently offer dedicated data center tax incentives, but states are already reassessing them, adding conditions, or considering repeal. Maine is the clean example: the state rejected a broader moratorium, but still moved to restrict certain data center projects from business development incentive programs.
The underwriting lesson is simple: treat incentives as upside, not base case.
If the project only works because a tax exemption survives untouched for ten years, the project is not robust. It is politically fragile.
The same is true for power tariffs. A large load tariff is the utility pricing and contract structure for very large customers like data centers. It can include upfront study payments, minimum contract terms, load ramp schedules, exit fees, security deposits, financial guarantees, and obligations to pay for grid upgrades. These are not footnotes. They decide whether the site actually works. Utility Dive reports 77 large load tariffs pending or in place across 36 states, with 29 approved in 2025 alone, compared with just 14 approvals from 2018 through 2024.
That means the tariff is part of the site.
The interconnection agreement is part of the site.
The utility’s posture is part of the site.
The regulator is part of the site.
A cheap headline power price means nothing if the tariff forces a rigid ramp, punishes load volatility, requires expensive upgrades, or creates stranded cost exposure. A buyer can win a low $/kWh and still lose the project.
This is why state selection is no longer just “cheap power good, expensive power bad.” Every market has a different constraint set. Texas has land, gas, fiber, and speed, but ERCOT congestion and transmission risk are real. Virginia has the deepest data center ecosystem in the world, but also rising load pressure, local opposition, and ratepayer scrutiny. The Midwest and interior markets are becoming more attractive because they can offer larger power blocks and more room to build, but those markets still need to be underwritten county by county, utility by utility, tariff by tariff.
The winners will not just pick the cheapest state.
They will pick the jurisdictions with the highest probability of delivered AI megawatts after accounting for interconnection, tariff structure, incentive durability, gas access, water, fiber, labor, zoning, and politics.
For operators, stop treating tax treatment and tariffs as external details. They are part of the product.
For buyers, diligence the tariff before you fall in love with the power price.
For investors, underwrite this like infrastructure. A site with a higher headline cost but a cleaner tariff, stronger utility relationship, and more durable political support may be worth more than a cheaper site that can collapse in approval, regulation, or rate design.
FPX view: incentives are no longer free money, and tariffs are no longer background paperwork. They are core capacity risk. If you do not understand the tax, tariff, utility, and regulatory stack, you do not understand the site.
10. Behind the meter is not magic. It is a power plant decision.
Behind the meter power is one of the most important trends in AI infrastructure.
It is also one of the easiest to oversell.
Behind the meter, or BTM, means some or all generation sits on the customer side of the utility meter. That can mean gas turbines, gas engines, fuel cells, batteries, or a hybrid microgrid. It can be used as bridge power while waiting for grid interconnection, supplemental power to reduce grid dependence, prime power for the data center, or islanded power where the site can operate largely on its own.
The appeal is obvious: grid interconnection is slow, AI demand is immediate, and waiting three to seven years for utility upgrades can kill the business case. BTM can move faster. That is why bring your own power and onsite generation are becoming normal in large scale planning.
But faster does not mean easier.
Grid connected power is simpler. BTM power is faster and harder.
A grid connected site still needs transformers, switchgear, UPS, generators, PDUs, cooling, and controls. A BTM site needs all of that plus fuel supply, generation equipment, step up transformers where needed, microgrid controls, protection studies, emissions systems, air permits, acoustic treatment, operations staff, maintenance contracts, and a plant management model that looks more like a utility asset than a colo hall.
That is the part the market underestimates. BTM is not a shortcut around complexity. It changes the complexity.
The critical path can move from utility interconnection to gas supply. Or turbine procurement. Or air permitting. Or emissions controls. Or noise. Or local opposition. Or the question of who actually operates the plant at 3 a.m. when the data center is under load and a unit trips.
A buyer or investor should ask the same questions every time:
Where is the fuel coming from?
Is the gas supply firm or interruptible?
Who operates the plant?
What emissions permits are required?
Is the site in a nonattainment area?
What noise limits apply?
What happens when the grid connection arrives?
Is this bridge power, backup power, prime power, or permanent islanded power?
What is the real cost per delivered AI megawatt after fuel, maintenance, redundancy, emissions control, and capex?
That last question matters most. BTM can look attractive when compared with waiting for the grid. It can look much less attractive when fully loaded with fuel, equipment, maintenance, redundancy, permitting, emissions treatment, and operational risk.
BTM is not cheap power.
BTM is speed, control, and complexity.
Use it when the cost of waiting for grid power is greater than the cost and risk of operating your own power system. Do not use it because it sounds sophisticated in a fundraising deck.
For operators, a credible BTM strategy can be a massive advantage. It can turn stranded land into deliverable capacity and create a bridge to permanent grid service. But only if the operator can actually execute the power plant layer.
For buyers, BTM diligence has to go beyond “is there power?” The real question is whether that power is permitted, fuelled, protected, dispatchable, financeable, and operable through failures.
For investors, BTM should change the underwriting model. You are no longer backing only a data center. You are backing a data center plus an energy asset. That can be valuable, but it deserves a different risk premium.
FPX view: behind the meter is not a slogan. It is an operating model. The market will reward serious BTM strategies and punish superficial ones. The operators who can combine grid strategy, onsite generation, fuel, controls, permitting, and data center operations will move faster than the grid. Everyone else is just adding another failure point.
11. Credit is now part of the product
This is the most underpriced shift in AI colocation: price no longer wins by itself. Providers are not just asking, will this customer pay rent? They are asking, will this customer strand my megawatts?
Stranded capacity is what happens when a provider commits scarce power, shell, liquid cooling, equipment, engineering time, utility queue position, and lender capacity to a buyer that fails to ramp. GPUs slip. Customers slip. Utilization slips. The hall sits half empty. The provider loses time, lender confidence, and the chance to allocate those megawatts to a stronger counterparty.
That is why weak credit can pay more and still lose. A hyperscaler, large enterprise, or sponsor backed neocloud with a credible ramp will beat a higher priced buyer that cannot prove durability. In this market, capacity is allocated to whoever can carry it, not whoever wants it most.
The winning buyer now needs two packages:
Credit package: financials, sponsor support, guarantees, deposits, letters of credit, insurance, customer contracts, offtake, prepayment, and balance sheet clarity.
Execution package: GPU delivery, energization date, cooling commissioning, network turn up, customer ramp, utilization plan, staffing, and operating readiness.
This is also where FPX adds leverage. The market is not one pool of capacity. Operators have different risk appetites. Some only want hyperscalers or investment grade enterprise credit. Some will work with sponsor backed neoclouds if the deposit, guarantee, offtake, or prepayment structure is right. Some will take more execution risk if the workload, timeline, and site economics fit.
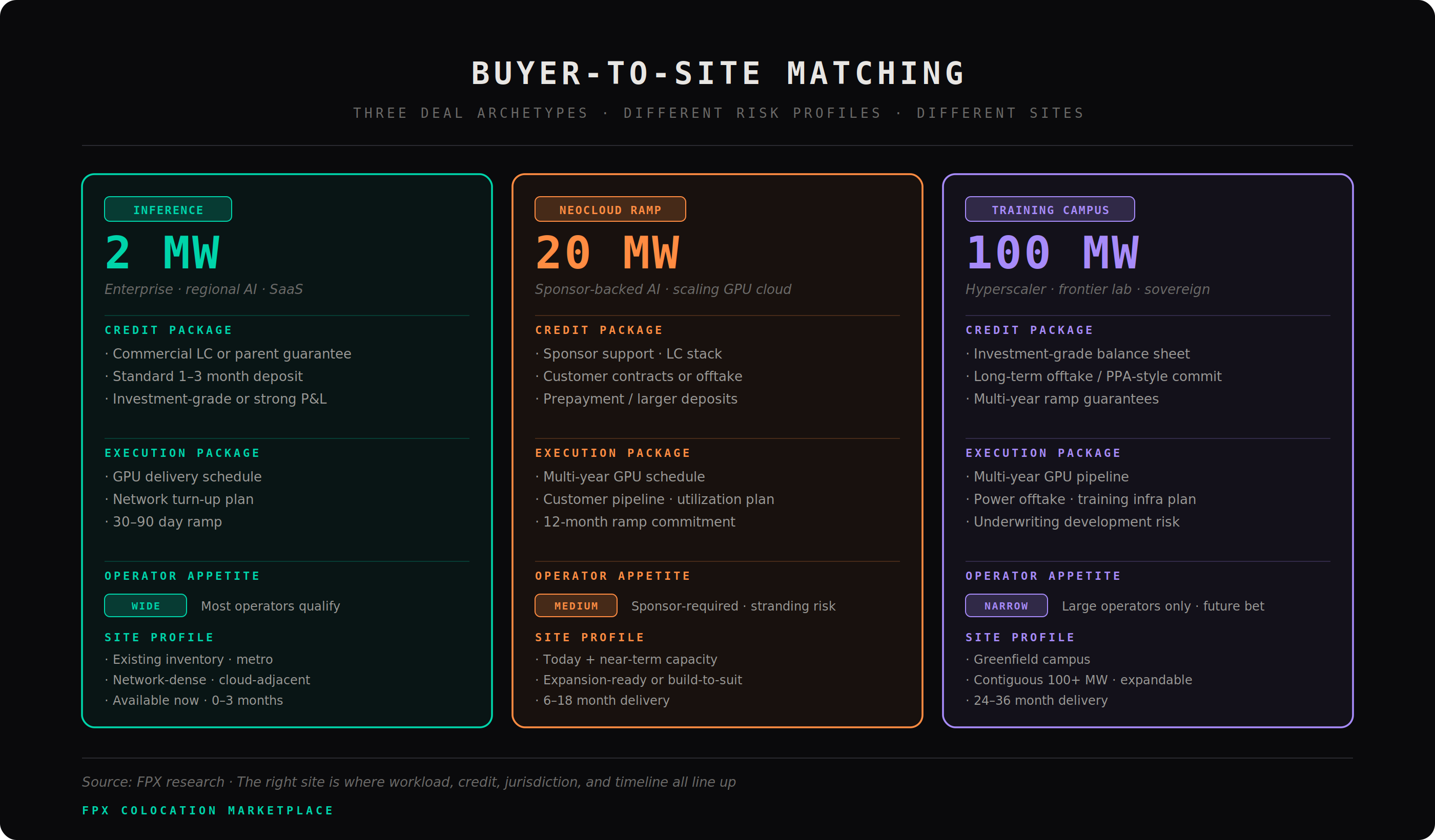
The job is not just to find capacity. It is to match the buyer’s workload, credit profile, ramp schedule, cooling needs, and risk tolerance to the operators most likely to actually accept the deal. A 2 MW inference deployment, a 20 MW neocloud ramp, and a 100 MW training campus should not be shopped the same way.
FPX view: credit is now a feature of capacity. The right site is not the cheapest $/kW. It is the site where technical design, commercial structure, operator risk appetite, and delivery probability all line up.

12. What the market should do now
The playbook is simple: stop selling AI-ready and start proving AI-deliverable.
For builders and operators, the product is no longer the hall. It is certainty. Show the one-line. Show the utility position. Show the substation path. Show transformer and switchgear status. Show generator strategy. Show the cooling topology. Show who owns the CDU. Show the failover case. Show the commissioning plan. Show the delay remedies. Show what density works today, what density works after upgrades, and what density this site will never support.
The operator that wins is not the one with the biggest headline MW number. It is the one that turns ambiguity into an underwritable product. Power, cooling, equipment, tariffs, permits, local politics, and tenant credit all need to be packaged as one answer: this capacity will exist, this is when it will exist, this is what it can run, and this is what happens if something slips.
For buyers, the rule is harsher: stop shopping for racks. Buy probability of delivered AI megawatts. The first question is not “what is the price per kW?” The first question is: can this site actually run my workload, at my density, on my timeline, with my cooling method, under my tariff, in this jurisdiction? If the provider cannot answer that clearly, the price does not matter.
That means buyers need to diligence the site like infrastructure. Where is the power coming from? Is the utility commitment real? What equipment is ordered? What permits remain? What tariff applies? What happens if one side fails? Who owns the liquid cooling boundary? What network paths exist? What local opposition exists? What expansion rights exist? Can the site support the next hardware cycle, or only the current one?
For neoclouds and fast scaling AI companies, demand alone is not enough. Bring a credit package and an execution package. Bring deposits, guarantees, offtake, customer contracts, sponsor support, GPU delivery schedules, network plans, cooling requirements, and a credible ramp. In this market, credibility travels faster than price. Weak buyers pay more, wait longer, get worse terms, and still lose.
For investors, stop underwriting data centers like shells. Underwrite them like infrastructure assets. A deliverable substation, a clean tariff, a supportive county, secured long lead equipment, credible cooling, and a financeable tenant are worth more than cheap land in a famous market. The premium belongs to assets with high conversion probability from announced megawatts to delivered megawatts.
The market is tight now and the best 2027 capacity will not arrive as clean open inventory. It will be preleased, repriced, reserved, or allocated to buyers with stronger credit and earlier commitments. Waiting for the market to “loosen” may feel conservative. It may actually be how you end up with the leftovers.
FPX view: the winners will be the groups that move from marketing to proof. Operators need to prove delivery. Buyers need to prove credit and execution. Investors need to prove the asset can survive power, permitting, equipment, politics, and tenant risk. Everything else is noise.
For teams that do not want to waste months chasing the wrong capacity, FPX can do this work upfront. Through the FPX Colocation Marketplace, we source and filter sites based on the factors that actually decide whether a deployment works: workload type, size, density, timeline, cooling requirements, power path, utility position, tariff exposure, legislation, local politics, operator risk appetite, and credit fit.
A 2 MW inference deployment, a 20 MW neocloud ramp, and a 100 MW training campus should not be sourced the same way. The right site is not just the site with available power. It is the site where the workload, infrastructure, operator, jurisdiction, timeline, and commercial structure line up.
That is what FPX is built to find. Not theoretical megawatts. Not brochure capacity. Sites that can actually support the deployment you are trying to build.
14. The FPX view: the market is not in a bubble. It is in a sorting cycle.
The AI colocation market is not breaking because some projects are getting canceled. It is breaking because too many people called undeveloped land “capacity.” Demand is real. Delays are real. Cancellations are real. Pricing pressure is real. The shortage is real. All of those can be true at once because the market is finally separating announced megawatts from delivered megawatts. The next wave of distress will not come from lack of AI demand. It will come from overlevered projects that confused planned power with usable power, confused tenant interest with financeable credit, and confused a rendering with an operating asset.
Here are the predictions that matter:
1. “AI ready” becomes a red flag.
Serious buyers will stop accepting vague claims. They will ask for one lines, failover cases, equipment status, cooling specs, commissioning proof, utility position, and delay remedies. If the operator cannot prove it, the capacity is not real.
2. The market splits into fake megawatts and financeable megawatts.
Fake megawatts get delayed, renamed, sold, or canceled. Financeable megawatts get preleased, repriced, and allocated to stronger buyers before they ever show up as open inventory.
3. Training and inference become different infrastructure markets.
Training wants massive power campuses, dense liquid cooling, and operators that can deliver 50 MW to 100 MW plus projects. Inference wants placement, latency, fiber, speed, and hardware flexibility. The market will eventually value them differently.
4. Credit beats price.
The highest bidder will not always win. The buyer that reduces stranded capacity risk will. Weak credit will pay more, wait longer, get worse terms, and still lose to a buyer the operator, lender, and utility can actually underwrite.
5. The county becomes part of the capacity stack.
Power, land, and fiber do not matter if the project dies in local politics. Noise, water, generators, tax abatements, transmission, ratepayer impact, and local benefit will decide which large campuses actually get built.
6. Electrical architecture becomes the next competitive frontier.
Cooling gets the headlines, but high density power delivery will decide which sites stay relevant. Sites that cannot migrate toward the next hardware cycle will be capped earlier than investors expect.
7. Behind the meter separates serious operators from tourists.
Everyone will pitch onsite power. Fewer will execute it. Behind the meter is not cheap power. It is fuel, permits, emissions, controls, operations, redundancy, and power plant risk wrapped into a data center strategy.
8. Tax incentives become less bankable.
States and counties will demand more from large load projects. Pro formas that only work because incentives survive untouched for ten years will break. Incentives should be upside, not the base case.
9. 2027 will not bring the relief buyers expect.
More capacity should arrive, but the best capacity will already be spoken for, repriced, or reserved for buyers with stronger credit and earlier commitments. Waiting for the market to loosen may be how buyers end up with leftovers.
10. The best assets will look boring.
The winners will not always be the biggest announcements or the cheapest land. They will be the sites where power, permitting, equipment, cooling, tariff structure, operator capability, tenant credit, and local politics all line up.
The mandate is simple. Builders need to stop selling future capacity as if it is commissioned capacity. Operators need to turn power, cooling, controls, tariffs, and liability boundaries into something buyers can actually underwrite. Buyers need to secure capacity now, but only real capacity. Investors need to underwrite AI data centers like infrastructure assets, not shells with power.
The old colo market sold space.
The new AI infrastructure market allocates delivered megawatts.
FPX exists for that market. Through the FPX Colocation Marketplace, we source sites based on workload type, size, density, timeline, cooling requirements, power path, tariff exposure, legislation, local politics, operator risk appetite, and credit fit. Not brochure capacity. Not theoretical megawatts. Capacity that has a real path to servers.
That is the game now. The winners will be the ones who understand it before everyone else is forced to.