
How GPT‑OSS Is Silently Reshaping Inference Optimization and Model Serving Sector— and How Neoclouds Can Capitalize

Introduction
OpenAI recently released its first open weight models since GPT2 called GPTOSS. Headlines fixated on benchmarks but the quiet story that most people missed out on is how this release restructures serving LLMs to the end user. It didn’t just drop weights—it packaged the right kernels (tuned for all major GPU families allowing users to run an optimized model out of the box for their GPU).They also provided ready-made integration hooks into the common inference engines people already use. With GPT-OSS pre-tuned for mainstream runtimes, the old advantage of ‘we run models faster’ for a few users/internally evaporates. The baseline is fast; what matters now is scale and orchestration.
From first principles, optimal LLM serving has two levels of optimization:
1. Inside a server (the engine): this is where the weights of the model actually live. Think of them like the recipe book the AI uses. Optimizing here means making sure that recipe can be read quickly and efficiently — no wasted steps. GPT-OSS largely solved this by shipping the weights already organized for the most common machines, so everyone starts with a “tuned engine.”
2. Between servers (the fleet): once you outgrow a single machine, the challenge shifts to how you spread that recipe across many kitchens without slowing down. This is where you decide where the memory of past conversations (the KV cache) sits, how often you can reuse it, and which machines should handle which parts of the work. That’s what NVIDIA’s Dynamo standardizes: it makes sure the kitchens talk to each other smoothly, so long conversations and tool calls don’t grind to a halt.
Once the box is standard, the economics migrate to the port: state locality (where the KV cache lives and how often you can reuse it) and capacity placement (which GPUs, on which interconnects, in which regions).
This is the terrain where inference optimization platforms like Together, Fireworks, Baseten, and peers—have operated, blending custom kernels with proprietary schedulers. But if model providers now ship models with those optimizations—and frameworks like Dynamo make multinode choreography baseline—does the “optimization” layer commoditize? Or does the moat re-form higher up, around how well you manage memory across sessions (global KV) and how reliable the agent experience feel—precisely where do Neoclouds and Investors/PE Funds capitalize on these changes?
Hold that thought. The rest of this piece maps where the moats are reforming—and how operators and investors can position before the market prices it in.
1) Inside the box: how GPT‑OSS standardizes single‑node optimization (and turns it into a commodity)
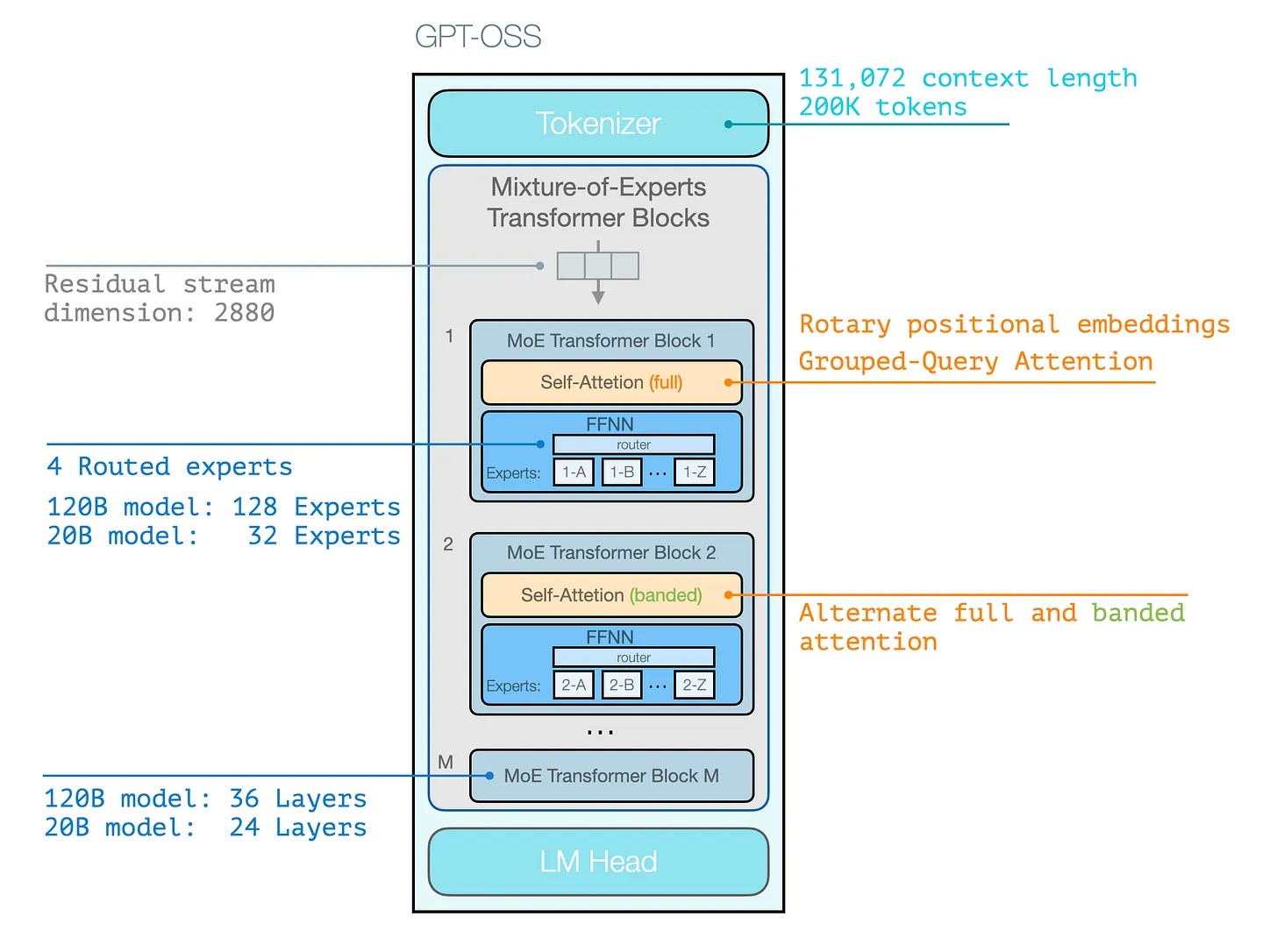
What GPT‑OSS actually ships for the node: not just open weights, but a serving recipe that makes one server fast by default. Two models—gpt‑oss‑20B and gpt‑oss‑120B —arrive with tool ‑use formatting (Harmony), pretuned‑ kernels, and dropin‑ paths through vLLM and Transformers. In practice that means: 20B runs on ~16 GB GPUs (most Gaming GPUs for the edge); 120B fits on a single 80 GB H100 (common datacenter class card); both support long contexts without bespoke engineering.
Why it’s fast on one box (simple version):
· Less math per token by design (Sparse MoE). Each token activates 4 experts out of 32 (20B) or 128 (120B), You get the same model capacity, but only a fraction of the compute per step.
· Smaller, cheaper weight movement (MXFP4 on MoE). MoE weights are stored in a custom 4-bit format (MXFP4) that packs multiple values into a byte, cutting memory traffic dramatically while keeping accuracy. That’s how these models fit in modest VRAM footprints.
· Attention matches the fast lane : The model’s attention pattern was chosen to line up with today’s fastest GPU code, so long conversations stay stable and you keep using the optimized kernels instead of slow fallbacks.
· The kernels are delivered to you. In Transformers/vLLM you flip a single config flag and the runtime fetches and loads the right kernels for your GPU (e.g., FlashAttention‑class paths). If a specific kernel isn’t available, it picks a compatible fast alternative. Making all the secret CUDA a one line option.
· The I/O format keeps you on the fast path. The models are trained for Harmony (channels for analysis/final and structured tool calls). Using the provided chat template avoids formatting mismatches that would push runtimes onto slower kernels.
GPT-OSS doesn’t drop off raw ingredients and leave you to prep; it delivers a meal kit with everything pre-chopped, portioned, and matched to your stove. Turn on the burner, and dinner is ready at restaurant speed—no kitchen hacks required.
The standard it sets and why intra‑node optimizations commoditize:
With GPT-OSS, the recipe for single-node speed is now out in the open. Mixture-of-Experts layouts, MXFP4 packing schemes, and attention patterns are not just described in papers—they’re baked into the model and maintained upstream by Hugging Face, vLLM, and NVIDIA. The tuned kernels are auto-pulled at install. That means one-off advantages like “we wrote a slightly faster matmul” don’t translate into lasting differentiation anymore. As soon as a kernel lands in the open-source stack, everyone has it.
For companies whose entire pitch rests on squeezing more tokens per second out of a single GPU, that’s a flashing red light. The ground they stand on is being standardized. The only real edge left at the node level is narrow and short-lived: earliest support for a brand-new silicon generation (e.g., Blackwell’s native MXFP4 tensor cores), or handling extreme constraints (ultra-low VRAM, mobile devices). For everyone else, peak tokens/sec per box is becoming table stakes—a baseline you get by running the blessed stack.
The constructive takeaway: if your company lives purely in the single-node optimization niche, it’s time to move up the stack. Future moats will form around fleet-level orchestration, global KV/state management, and agent runtime quality, not around shaving a few microseconds off matmuls. Otherwise, as GPT-OSS and Dynamo raise the floor, the optimization business becomes a race to zero.
2) Across the fleet: Dynamo, the autopilot for inter‑node optimization
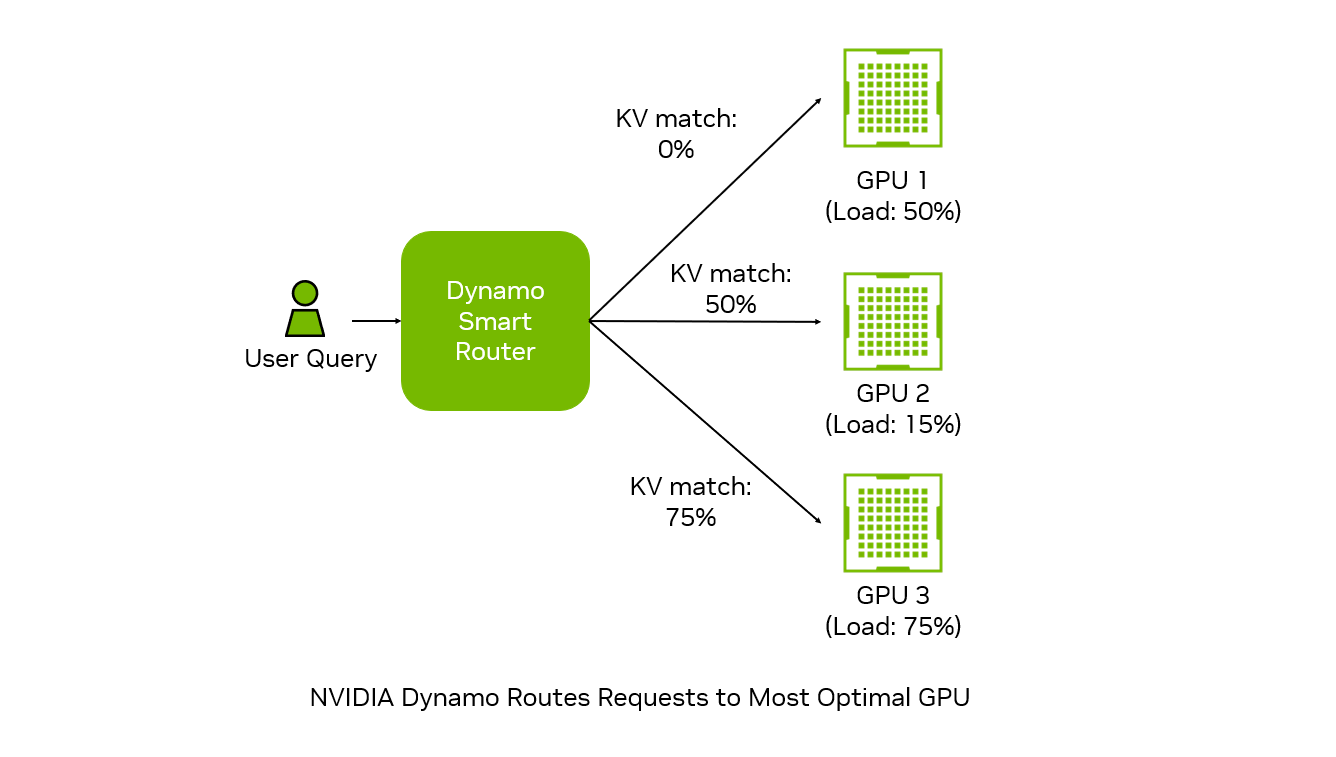
If GPT‑OSS standardized the engine, NVIDIA Dynamo is the autopilot that flies the fleet. Think of it as the control tower above your runtime (vLLM, TensorRTLLM‑, SGLang, PyTorch) that quietly handles the messy between ‑servers work so your service stays fast and predictable.
What Dynamo automates:
· Prefill vs. decode become separate stations. Long prompts go to heavy-duty prep cooks, while token-by-token generation is handled by line cooks trained for speed. They work in parallel, instead of tripping over each other.
· Conversations stay near their memory. Sessions are pinned close to where their KV cache lives, so context doesn’t need to be rebuilt every turn. Time-to-first-token stays flat even as histories grow.
· Hot vs. cold state is managed intelligently. Active memory lives on fast HBM, while colder chunks are pushed to cheaper RAM or disk. The right pieces are always within arm’s reach.
· Traffic is steered by the fabric, not by chance. Requests are batched when it helps, split when it doesn’t, and routed according to NVLink or InfiniBand realities—avoiding tail-latency pileups.
Net effect: Dynamo takes a decade of hand ‑rolled internode tricks—custom batchers, ‑adhoc‑ prefill pools, cache pinning/migration—and makes them the default. It lifts the baseline for cluster performance the same way GPT‑OSS lifted the baseline for single ‑server performance.
Market impact
When fleet behavior is standardized, the old “we invented a better scheduler” pitch loses altitude. Differentiation shifts to two places:
Upstack‑: turning primitives into products—global KV as a service (policy, isolation, observability), agent ready‑ APIs (tool loops, retries, structured outputs), and developer ergonomics.
Down‑stack: scale and placement—who actually has next‑gen GPUs, NVLink/IB topologies, pre-warmed pools, and sovereign regions turn “we have GPUs” into contractual SLAs on latency, reliability, and compliance.
3) Where this leaves Baseten, Fireworks, Together (and the Next-Wave Platforms)
These teams didn’t get here by accident. They’ve lived in both worlds—inside the server (kernels, memory layouts, quantization) and across the fleet (batching, routing, cache reuse). Dynamo doesn’t erase that expertise; it repoints it. When the fleet’s “autopilot” becomes standard, the pitch shifts from “our scheduler is smarter” to “our service turns state into speed”. In practice that means packaging global KV (the model’s short term‑ memory) as a product with policy, isolation, and observability; presenting agent ready‑ APIs that make tool calls reliable; and turning goodput SLAs (flat Time to first token (TTFT) under long prompts, stable latency during tool loops) into the headline—because that’s what customers actually feel.
Each platform already has a lane:
· Baseten wins on product surface and enterprise posture—Truss-style packaging, safe rollouts, autoscaling, and the ability to “run in my VPC.” It appeals to teams that want compliance and integration, not infrastructure tinkering.
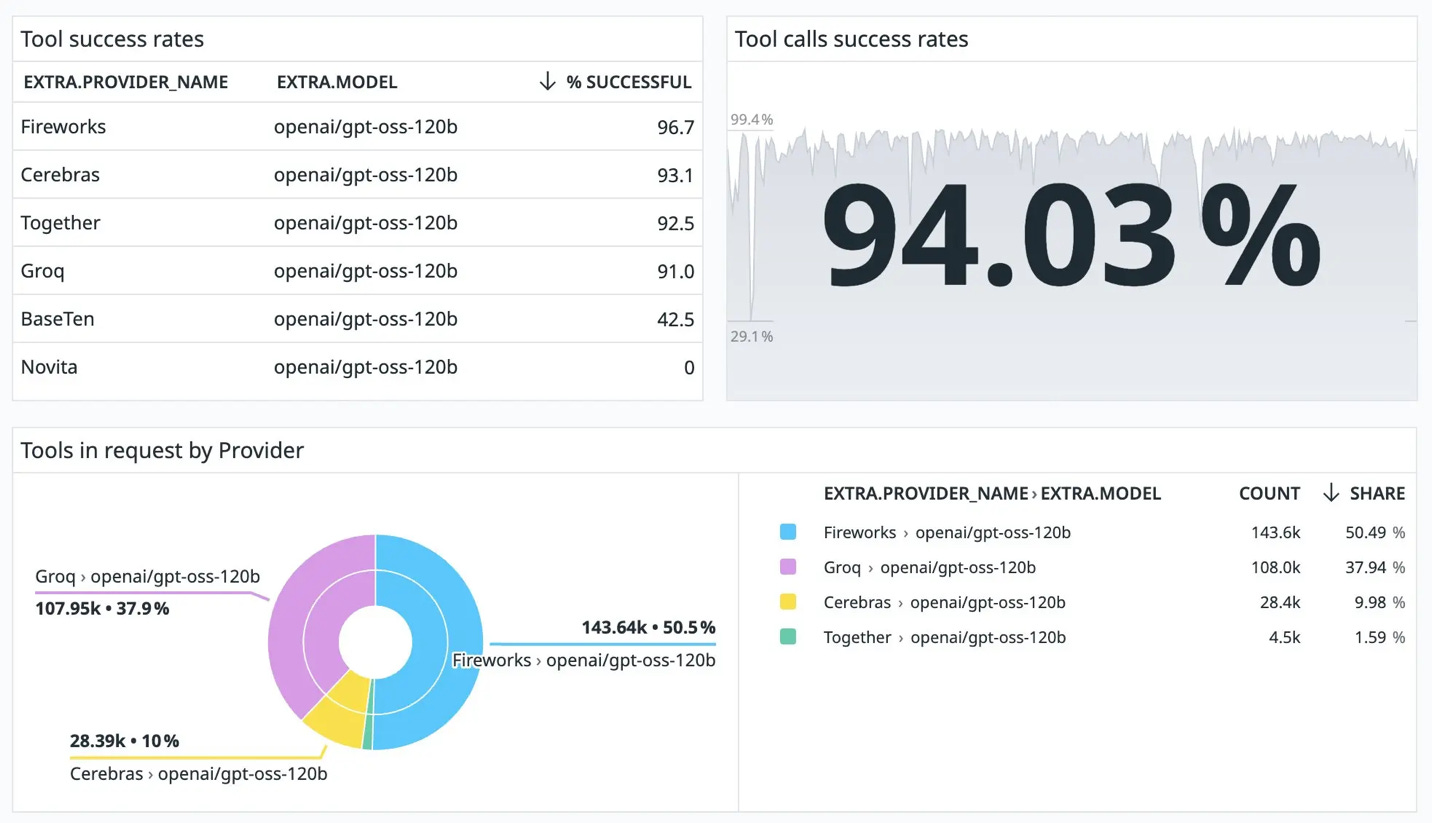
· Fireworks leans into the runtime and agent layer—OpenAI-compatible endpoints, structured outputs, and a latency/cost story developers can adopt in an afternoon. OpenRouter usage shows Fireworks already leading in tool-calling success (96% vs peers in the 90–93% range), validating that this focus is translating into reliability customers notice.
· Together plays the silicon-first card—early adoption of the newest GPUs, FlashAttention pedigree, and relentless speed on distributed training. It positions them as the open-model factory for ambitious runs, making them the most natural partner for large-scale infra.
None of that collides with Dynamo; if anything, Dynamo raises their floor so they can spend more calories on the parts customers touch—and less on re‑implementing the same orchestration primitives.
But there is still an unavoidable differentiator that infrastructure companies need to take into account. Standardization raises the floor, but it doesn’t erase the ceiling—there are key moves neoclouds and inference platforms can make to turn commodity capacity into defensible advantage. In the next sections, we explore what those moves are and recommend specific partnerships and strategies that can take these businesses to the next level—and why the boards of these companies should be thinking about this now, before the market prices it in.