
The NeoCloud Guide to Robotics: Inside the Next Compute Gold Rush
The next wave of AI is not chat but machines acting in the real world. That shift will create new winners across compute, data, and infrastructure.

The thesis in 3 bullets
The unit shift: In LLM land, cloud yield is tokens/sec. In robotics, the dominant unit becomes high‑quality experience hours (real + synthetic). Neoclouds win by maximizing Experience Yield, not peak TFLOPS.
The infrastructure split: Robotics creates two giant cloud shapes:
Scale‑up brain training (world models / foundation policy backbones) → rack‑scale fabrics and high‑bandwidth memory.
Scale‑out experience production (simulation + synthetic data generation + regression) → throughput clusters and brutal storage/network economics.
Neoclouds that only buy “the biggest rack” will fail on margin.
The moat: The winning robotics cloud isn’t the one with the most GPUs; it’s the one that solves (a) the Optical Tax (data movement costs of thick sensor logs) and (b) Asset Ops (versioning the physical world as reliably as code).
Disclaimer: This is not investment advice. It’s an analytical framework
+ a public-market watchlist for understanding how “robotics workloads”
could re-route compute spend across the stack. Do your own work /
consult a licensed professional before acting.1) Why robotics is the next stress test for neoclouds
Neoclouds were born in an era where the dominant workload was simple to describe: train or serve large models. The customer asked for more GPU memory, faster interconnect, more tokens, lower $/token. The data looked like text and embeddings; it moved cheaply, and it compressed well.
Robotics breaks that mental model.
Robots are “AI systems” that must survive physics, latency, safety constraints, regulatory constraints, and messy real‑world distribution shifts. A robotics company’s competitive advantage isn’t just model weights — it’s the closed loop: data → learning → evaluation → deployment → more data. And that closed loop runs on thick telemetry: multi‑camera video, lidar/radar streams, IMU, joint states, tactile signals, audio, maps, event logs, and operator feedback.
This isn’t theoretical scale. Industrial robotics continues to compound. The latest World Robotics statistics (via the International Federation of Robotics) reported 542,000 industrial robots installed in 2024, and forecasts suggesting the 700,000 annual mark will be surpassed by 2028.
So the question isn’t “will robotics use compute?” It’s: what kind of compute, where, and packaged into what product?
McKinsey’s critique of neoclouds is the right framing: BMaaS economics are fragile; long‑term viability requires moving “up the stack” into AI‑native services. Robotics is one of the cleanest “up‑the‑stack” opportunities because the infra primitives alone are not enough — the workflow plumbing is where the pain lives.
But there’s a trap: neoclouds shouldn’t try to be a robotics software company. The win is orchestration — being the place where robotics stacks run 10× faster and cheaper than generic cloud.
Hold that thought. First we need a shared mental map of robotics workloads.
2) Robotics workloads 101 — a quick mental map
Most robotics stacks can be understood as three loops with different latency and compute constraints:

Loop 1: Reflex / Control (milliseconds, on‑robot)
Motor control, stabilization, safety interlocks
Perception at sensor rate (vision, lidar, tactile preprocessing)
Local state estimation and fast collision avoidance
Constraint: deterministic latency and safety → edge compute.
Loop 2: Assist / Supervision (tens to hundreds of ms, edge + nearby compute)
Higher‑level perception fusion
Local planning with bigger context
Teleoperation and human‑in‑the‑loop interventions
Fleet “assist” services: map updates, localized reasoning, anomaly detection
Constraint: network jitter becomes the bottleneck before FLOPS. This is where “regional edge POPs” matter.
Loop 3: Improve / Learn (minutes to days, mostly cloud + some on‑prem)
Training policy models, vision backbones, VLA/VLM adapters
Reinforcement learning (RL), offline RL, imitation learning
Simulation, synthetic data generation (SDG), domain randomization
Regression testing and evaluation harnesses
Dataset curation, labeling, provenance, compliance
Constraint: throughput, reproducibility, cost → the domain of clouds, but not “generic” clouds.
If you internalize these three loops, the edge/cloud split becomes obvious:
robots do actions at the edge; clouds manufacture improvement.
That’s why the right metaphor for neoclouds in robotics is not “robot factories” (sounds like hardware). It’s Experience Refineries: facilities that take raw telemetry ore and refine it into policy gold.
3) Types of robots — and why “robotics” isn’t one workload
Robotics isn’t a single market; it’s a set of workload families with different “experience physics.”
A) Industrial arms (ABB (ABB), FANUC (6954.T), etc.)
Structured environments, repetitive tasks
High value on reliability, calibration, and deterministic behavior
Data is often proprietary and deployment environments are sensitive (IP, safety)
Compute shape: more regression testing, digital twins, PLC integration; less open‑world reasoning (for now).
B) Mobile robots in warehouses / logistics
AMRs, picking, sorting, inventory
Rich perception (cameras + depth), but environments still semi‑structured
Heavy focus on fleet management, uptime, and map/scene updates
Compute shape: lots of fleet ops + incident replay + simulation of edge cases.
C) Drones / aerial systems
Tight power budgets
Intermittent connectivity
Strong need for on‑device autonomy; cloud used post‑flight for analytics + training
Compute shape: edge-first inference, cloud for after‑action learning and simulation.
D) Autonomous vehicles / robotaxis (Alphabet (GOOG/GOOGL) subsidiary Waymo as an existence proof)
Extreme safety requirements
Massive logged datasets + rigorous simulation requirements
Closed-loop evaluation is the product
Waymo has explicitly studied scaling laws in autonomous driving for motion forecasting and planning, reporting predictable gains as compute/data scale.
That matters because it signals that “bigger models + more compute” isn’t only an LLM story — but the evaluation loop is far stricter.
E) Humanoids (Tesla (TSLA), plus many private players)
Humanoids are the most compelling “generalist robotics” narrative — but they are also the most operationally messy. They’re currently defined by:
multi‑modal perception,
dexterous manipulation,
and early-stage reliance on teleop / human-in-the-loop.
This is important because teleoperation is a near‑term cloud workload even before autonomy is “solved.” More on that later.
F) Soft robotics / medical / bio‑inspired systems
High-fidelity physics, contact dynamics, deformables
Simulation becomes harder and often more CPU‑bound or specialized
Compute shape: pushes more “physics correctness per dollar,” not just rendering.
The takeaway: robotics workloads fragment by robot type. The neocloud product must be modular — not “one GPU SKU fits all.”
4) Training, RL, synthetic data — where the real cloud spend lives
This is where robotics starts to look less like “inference at scale” and more like “manufacturing at scale.”
4.1 Training is no longer just “pretrain + finetune”
Robotics training is increasingly a blend of:
Foundation backbones (vision, VLM/VLA, world models)
Behavior cloning / imitation learning (from demos, teleop, logs)
Offline RL (learning from logged behavior)
Online RL (learning from simulation and, carefully, real fleet)
Tool‑using agents (planning, reasoning, memory, retrieval, constraints)
This is why “world models” matter: they compress physical interaction into learnable structure. And why robotics teams talk about “foundation models” differently: the model must predict outcomes in the world, not just tokens.
4.2 Synthetic data generation (SDG) is the new pretraining corpus
For a lot of robotics categories, you will never get enough real-world rare events:
corner cases in warehouses,
unusual lighting/weather,
rare contact events,
edge-case human behaviors,
safety-critical near-misses.
Simulation and SDG are how teams buy coverage.
You can see SDG tooling converging from multiple ecosystems:
Unity Software (U) ships a Perception toolkit for generating large-scale synthetic datasets for computer vision training and validation.
Epic Games’ Unreal Engine ecosystem is used for photorealistic virtual environments; companies like Duality discussed adopting USD as a standard format for large environment datasets and real-time simulation workflows.
Physics engines like MuJoCo have been open-sourced by Google DeepMind and are widely used for control/RL research.
Gazebo supports choosing physics engines at runtime via an abstraction layer — useful for experimentation and for matching simulation fidelity to task requirements.
This diversity matters for neoclouds: the cloud must run all of it, not just one vendor’s stack.
4.3 Log-based synthetic simulation becomes a first-class primitive
A lot of autonomy teams don’t generate worlds from scratch — they start from reality and perturb it.
Applied Intuition (private) describes log-based synthetic simulation as using real-world data within controlled simulation environments to improve validation and safety.
This pattern generalizes beyond AVs: “log → replay → perturb → evaluate” is becoming a standard robotics engineering workflow.
The implication for neoclouds: storage + ingest + replay pipelines become as important as GPUs.
5) What’s the “inference equivalent” for robotics?
If you come from LLM infrastructure, “inference” means: serve tokens; optimize latency and throughput; measure tokens/sec and $/1M tokens.
Robotics “inference” is not a single thing. It’s a hierarchy:
5.1 Act vs Think: the hybrid autonomy model
A durable architecture pattern is:
Small, fast model (“act”) runs on the robot: low-latency control and policy execution.
Large, slow model (“think”) runs off-robot (often cloud or nearby edge): planning, long-horizon reasoning, tool use, memory, scenario analysis.
An agentic system ties them together: policy constraints, safety checks, fallback behaviors, and the ability to ask for help (teleop).
This is not hype — it’s forced by physics and reliability. If your robot needs 10–20 ms control loops, cloud round trips don’t fit. But cloud is still valuable as:
long-term memory,
fleet-level learning,
and heavy reasoning/analysis that can tolerate latency.
5.2 The teleoperation bridge (the underrated near-term workload)
Before policies are fully autonomous, many robots — especially humanoids — rely on:
VR/AR operator interfaces,
multi-camera video streaming,
low-latency relay servers,
and continuous recording for later learning.
This creates a “robotics inference” workload that looks like:
real-time video ingest + transcode + relay (edge POPs),
operator session management (security, audit logs),
labeling hooks (marking moments of intervention),
and policy improvement pipelines that turn teleop into training data.
This is immediate revenue before the “world model” is perfect.
5.3 The important nuance: cloud doesn’t replace edge — it weaponizes it
Robots with good edge processors still need cloud because:
you need to train and continuously improve,
you need fleet analytics and regression,
you need simulation and SDG,
and you need to manage the digital twin / asset graph.
Edge compute reduces bandwidth and improves autonomy — but it increases the value of cloud as an improvement engine.
6) Hardware: what neoclouds actually need — and what to stop buying by reflex
This is where the robotics workload map turns into a build plan.
6.1 The core idea: robotics forces a “two-cloud” hardware strategy
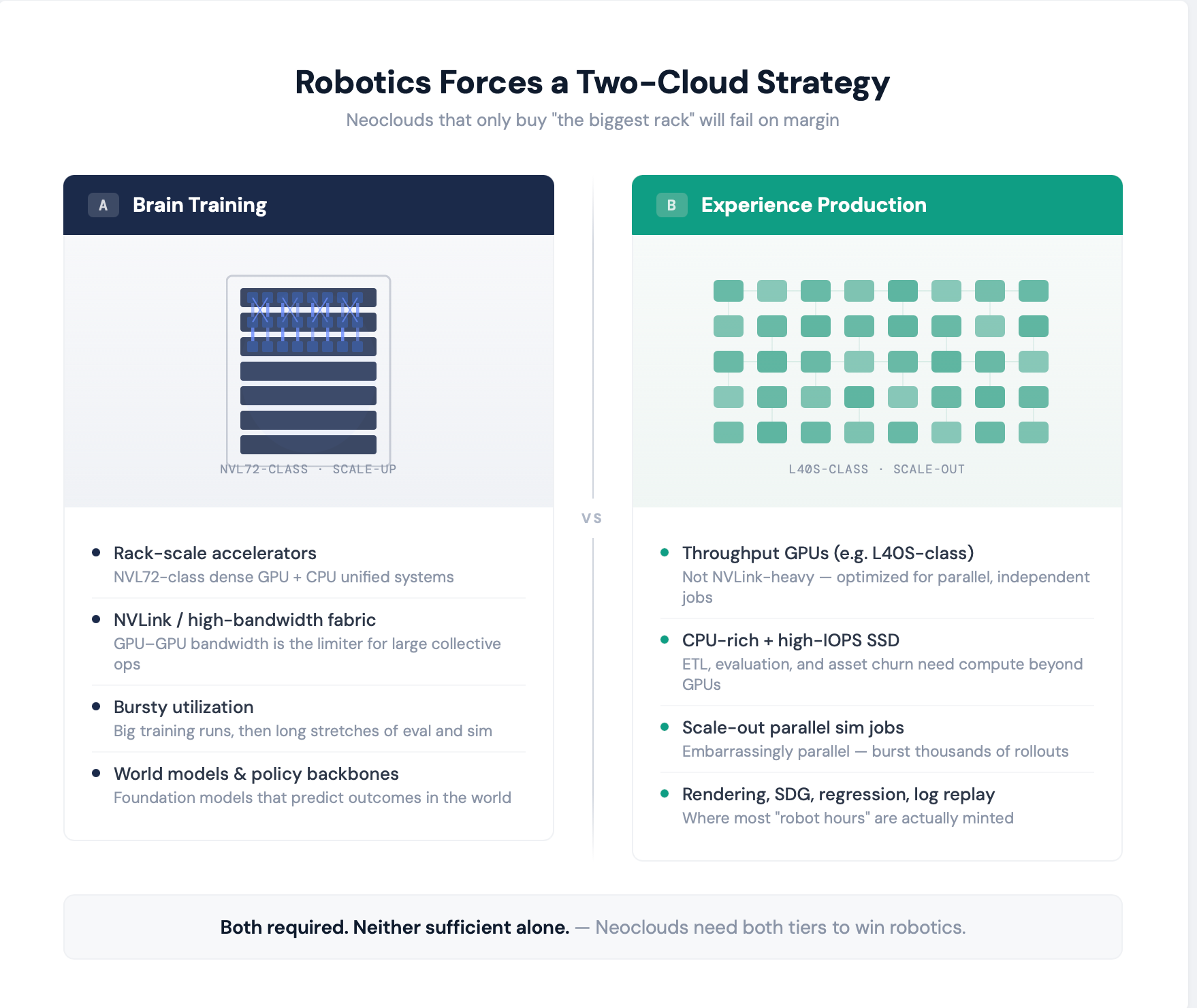
Neoclouds that only optimized for “big model training” will miss the largest volume workload in robotics: experience production.
You need two primary hardware domains:
Domain A: Brain training (scale‑up + high‑bandwidth)
These are your “world model / backbone” clusters: large models, large activations, big collective ops, high bandwidth.
Rack-scale systems like NVIDIA’s Vera Rubin NVL72 are explicitly positioned as a rack‑scale AI supercomputer unifying 72 GPUs and 36 CPUs with high-speed interconnects.
You can treat “NVL72-class” as a proxy for the scale‑up direction of travel: dense accelerators + fast fabrics.
But here’s the key: most robotics companies will not run these 24/7 at full utilization. Their demand will be bursty: big training runs, then long stretches of evaluation and sim.
Domain B: Experience production (scale‑out throughput)
This is where most “robot hours” are minted:
simulation rollouts,
rendering,
SDG,
regression,
log replay and perturbation.
This workload often doesn’t need NVLink-scale fabrics. It wants:
cheap GPU throughput per dollar,
strong video/graphics pipelines,
lots of CPU,
fast local SSD,
and a storage backend that doesn’t collapse under asset churn.
Mid-tier “universal” GPUs like the NVIDIA L40S are marketed for both AI and graphics/video workloads, including 3D graphics, rendering, and video.
Whether it’s L40S specifically or an equivalent class, neoclouds need a render/sim farm tier that is not priced like frontier LLM training.
6.2 NVLink isn’t “overkill” — it’s just not the default answer for sim farms
A fair critique is: “Simulation is parallel. Why pay the NVLink tax?”
The honest answer:
Most sim farms are embarrassingly parallel → scale‑out wins.
NVLink-scale becomes valuable when you’re synchronizing multi‑agent environments tightly, training giant world models, or doing massive multi‑modal joint training where GPU–GPU bandwidth becomes a limiter.
So the clean position is:
NVL72-class is the “brain trainer.”
Throughput clusters are the “experience factory.”
Neoclouds need both.
6.3 The robotics “Optical Tax” — and the nuance that makes it real
Robotics fleets generate thick telemetry. If you assume:
multiple cameras,
high frame rates,
and continuous recording,
you can easily land in “petabytes per day” territory.
But there’s a nuance worth stating explicitly to sound credible:
Inside a data center, terabit-scale networking is manageable. The issue is not switch port capacity.
The cost lives in the WAN transit bill, ingest architecture, and the operational friction of moving, storing, and curating multi‑modal logs at scale.
This is why edge preprocessing is not just a technical preference — it’s a solvency requirement.
And it connects directly to optical networking trends. Companies like Marvell (MRVL) highlight 800G coherent pluggable optical modules (ZR/ZR+) for multi-site AI training and data center interconnect, enabling geographically distributed clusters.
Meanwhile, NVIDIA (NVDA) leadership has publicly signaled that co-packaged optics are promising but may take until 2028 or beyond for broad adoption, citing reliability constraints.
Translation for robotics neoclouds:
You don’t “wait for optics” to solve your data plane. You design for bandwidth scarcity now by pushing:
compression,
event-triggered logging,
on-device embeddings,
and selective upload.
Cloud value shifts from “store everything” to “refine the right things.”
6.4 Edge hardware is already good enough to change cloud economics
Two examples (not as endorsements — as proof that edge compute is real):
NVIDIA Jetson Orin Nano modules deliver up to 67 TOPS with 7W–25W power options.
Qualcomm (QCOM) Robotics RB6 advertises 70–200 TOPS (INT8) at low power.
As edge gets stronger, the cloud’s role becomes less about “real-time autonomy” and more about:
training,
simulation,
evaluation,
fleet analytics,
and long-horizon coordination.
6.5 A practical hardware map: workload → where it runs → what it needs
Below is a “useful, not perfect” mapping. Treat ratios as rules of thumb, not laws.
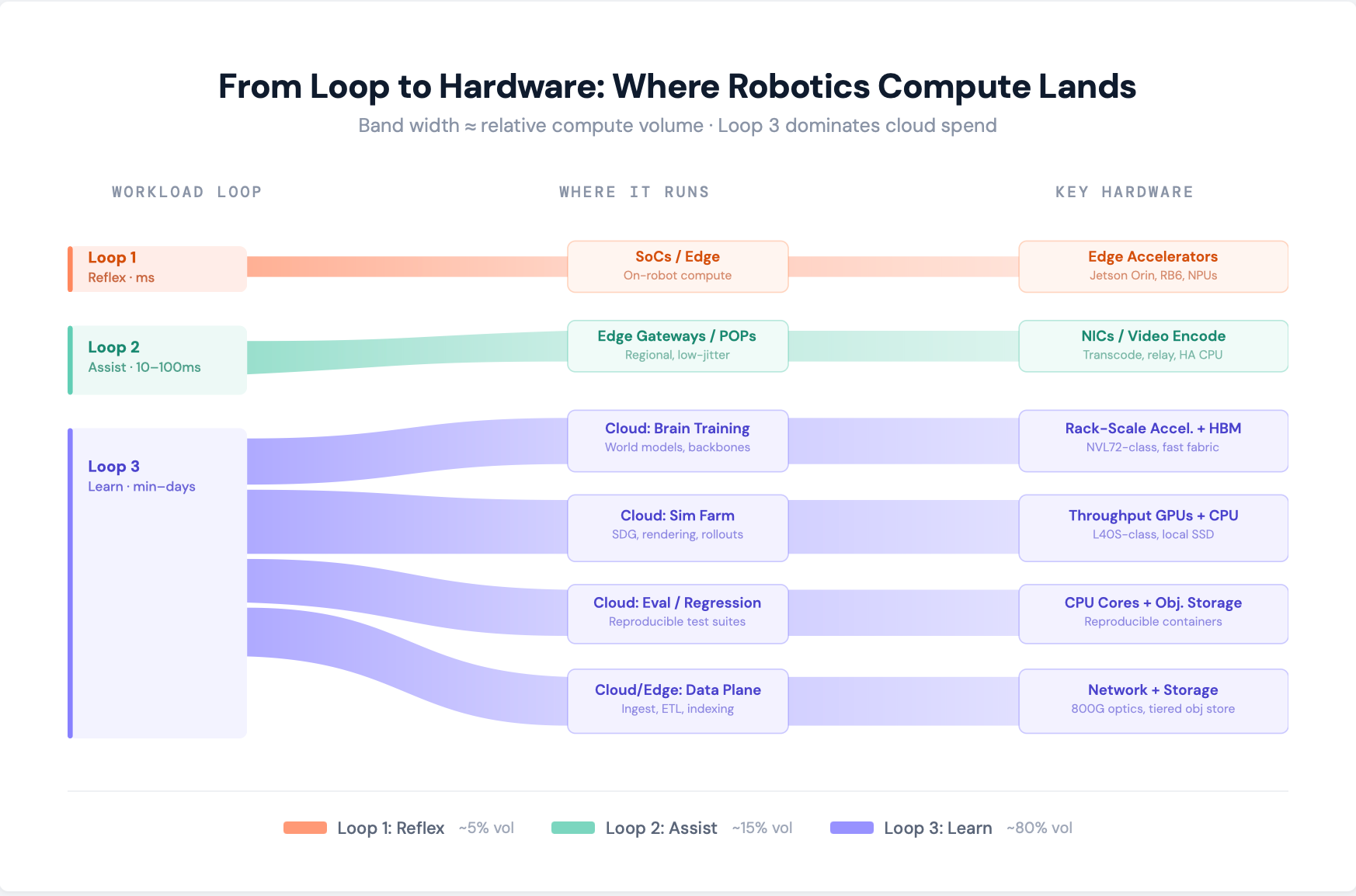
Loop 1 (on-robot reflex)
Runs on: SoCs / embedded GPU/NPUs + microcontrollers
Optimized for: latency, determinism, power
Key hardware: edge accelerators; fast local memory; sensor IO
Loop 2 (assist + teleop)
Runs on: edge gateways + regional POPs + sometimes on-prem “micro-cloud” racks
Optimized for: jitter, video relay, security
Key hardware: NICs, video encode/decode accelerators, moderate GPUs for transcode and perception assist, high-availability CPU
Loop 3 (learn/improve)
Split into sub-factories:
World model / backbone training
Runs on: cloud + sometimes on-prem (large players)
Hardware: rack-scale accelerators + high-bandwidth fabrics; strong networking; DPUs/NICs
Sim + SDG farms
Runs on: cloud (best case), sometimes on-prem for proprietary environments
Hardware: throughput GPUs (often not NVLink-heavy), CPU-rich nodes, high-IOPS local SSD, and a storage tier that can sustain asset churn
Evaluation + regression
Runs on: cloud, often CPU-dominant
Hardware: many CPU cores, fast object storage access, reproducible container runtimes
Data plane (ingest, ETL, indexing)
Runs on: wherever data lands (cloud regions + edge POPs)
Hardware: network + storage first; CPU; GPUs optional (embeddings, video preprocessing)
6.6 The overlooked cost center: energy and cooling
Robotics workloads amplify infrastructure constraints. Simulation farms are compute-heavy and storage-heavy; “move everything” data strategies hit both cost and power walls.
The IEA projects global data center electricity consumption could double to ~945 TWh by 2030 in a base case.
That’s not a robotics-specific number, but it’s the macro constraint that makes robotics data plane efficiency a competitive advantage, not a moral footnote.
7) The neocloud robotics software stack — don’t build everything, orchestrate the ecosystem
Here’s the highest-conviction point for neoclouds:
Robotics isn’t missing GPUs. It’s missing production-grade workflow plumbing.
Neoclouds should not try to write the physics engine; they should make the robotics ecosystem run 10× better on their infrastructure than on generic cloud.

The evidence is in the scars. AWS RoboMaker (Amazon (AMZN)) is a cautionary example: AWS announced it would discontinue RoboMaker support on September 10, 2025.
You can interpret that many ways, but one lesson is clear: building a full robotics application layer as a cloud provider is hard — and not always strategic.
So what should neoclouds do instead?
7.1 SimOps: the “Kubernetes for simulation factories”
What customers need:
orchestration of massive numbers of sim jobs (burst + drain),
deterministic runs and replayability,
cost-aware scheduling,
fast startup times (container images + environment assets),
cross-engine support (Unity, Unreal, Isaac, MuJoCo, Gazebo, proprietary).
Neocloud SimOps value-add:
asset-aware scheduling: schedule jobs where the assets already live (cache locality)
time-to-first-frame optimization: pre-warm images, pin common scenes, build “sim base images”
license-aware scheduling: for commercial engines
7.2 The Robotics Data Plane: “thick telemetry” ingest, refinement, and retrieval
This is the core product opportunity — the Experience Refinery.
What customers need:
ingestion endpoints close to fleets,
compression + filtering pipelines,
object storage with predictable performance,
indexing of multi-modal logs,
dataset lineage and provenance,
“search by behavior” (find similar failure modes),
and the ability to turn logs into training-ready shards.
Neocloud value-add:
edge POP ingest + direct peering: lower transit costs and jitter
GPU-optional preprocessing: embeddings, segmentation, event detection
policy-aware logging hooks: “log what matters” and tag with policy version, environment, and operator actions
7.3 Asset Ops: “Git for 3D worlds” (the boring moat)
Robotics simulation doesn’t scale without asset hygiene:
meshes, textures, materials,
environment graphs,
robot URDFs,
sensor models,
physics parameters,
and every change must be versioned, validated, and reproducible.
This is where OpenUSD becomes relevant as a common language.
Neocloud Asset Ops value-add:
high-IOPS tiers for asset registries,
automated asset validation and compatibility checks,
diffing/versioning for 3D worlds,
promotion pipelines (dev → staging → prod),
and “asset provenance” tied to training runs and evaluations.
This is where infrastructure becomes sticky. Switching your GPU provider is easy. Switching your world versioning system is painful.
7.4 PolicyOps + EvalOps: the production line for autonomy
Robotics companies don’t just train models — they ship policies into physical systems.
What customers need:
policy registries,
reproducible builds,
evaluation harnesses (open-loop and closed-loop),
safety gates,
rollback tooling,
A/B testing for fleets,
and post-deploy monitoring tied back to training data.
This is where “Experience Yield” becomes measurable.
A usable definition (the one that will age well):
Experience Yield is the amount of real + synthetic experience that moves your evaluation curve per dollar and per day, weighted by coverage and downstream impact.
Neoclouds can offer this as a dashboarded KPI, not a vibe.
7.5 FleetOps integrations: speak the ecosystem’s language
To be credible, neoclouds have to integrate with the existing robotics substrate:
ROS 2 middleware variants, QoS complexity, mixed networks
ROS 2 supports non‑DDS middleware implementations like Zenoh, and documentation exists for installing rmw_zenoh.
This matters because robotics fleets often run over unreliable networks, and communication layers are evolving.
Also, “cloud robotics” frameworks exist in the wild: SAP (SAP) maintained an adaptation of the open-source Google Cloud Robotics platform to provide infrastructure for building and running robotics solutions (Cloud Robotics Core).
You don’t need to copy it — you need to be compatible with these patterns.
7.6 Partnership strategy: the “render farm” analogy
This is how you avoid the build-vs-partner trap:
Don’t build Isaac Sim. Make Isaac-based pipelines run cheaper and faster on your infra.
Don’t build Applied Intuition. Make log replay and synthetic perturbation pipelines run at higher throughput with lower storage + transit costs.
Don’t build Unity or Unreal. Build the scheduling, caching, and storage tiers that make SDG industrial.
Your role is to be the best substrate for the best tools.
8) The counter-argument: “why wouldn’t robotics companies just do on-prem?”
They often will — especially the biggest players with the most proprietary data.
So the neocloud thesis must be strong enough to survive that.
8.1 Elasticity is the obvious advantage — but not the only one
The simplest “cloud win” is bursty simulation:
You might need 5,000 GPUs for 6 hours of regression testing after a major change, then 200 GPUs for the rest of the week.
Owning for the peak is wasteful; renting for bursts is rational.
This is classic cloud math — but robotics intensifies it because sim/regression patterns are spikier than steady inference.
8.2 Hardware diversity: neoclouds as the “compute junk drawer” (in a good way)
Robotics orgs need a weird mix:
frontier accelerators occasionally,
mid-tier GPUs constantly,
CPU-heavy boxes for evaluation,
high-IOPS storage nodes for asset ops,
and network-heavy POPs for teleop/ingest.
Most companies don’t want to own that entire long tail. Neoclouds can.
8.3 A more subtle win: vendor-neutral orchestration
If the ecosystem continues to fragment (NVIDIA stack, open-source stack, custom accelerators), robotics companies will value portability and multi-engine pipelines.
Neoclouds that become “the portable factory floor” — where workflows can run across GPU types and simulation engines — can be strategically valuable even when some training stays on-prem.
8.4 Data gravity isn’t a death sentence — it’s a product opportunity
If “moving data” is too expensive, neoclouds can:
build ingest POPs near customers,
offer private connectivity/peering,
ship “edge refinery” appliances (managed ingest + preprocessing),
and only move refined experience, not raw ore.
That’s how you compete with on-prem: meet the data where it is, then refine.
9) Where the real alpha is for neoclouds (and how to package it)
Robotics infrastructure becomes valuable when it is sold as a closed-loop productivity system, not compute.
9.1 Productize Experience Yield
In LLMs, the KPI is tokens/sec. In robotics, the KPI should be something like:
Experience Yield per $
Coverage per week (how many environments, lighting conditions, contact states, failure modes)
Eval uplift per 1,000 hours of experience
Time-to-regression (how fast you can validate a new policy safely)
Neoclouds can host the dashboards, the evaluation harnesses, and the provenance graph that ties it all together.
9.2 Monetize the “factory stages,” not just the machines
A durable robotics neocloud will have multiple revenue lines:
Sim Farm compute (throughput GPUs + CPU-heavy nodes)
Asset Ops storage tiers (high-IOPS + object storage + caching)
Telemetry ingest + preprocessing (edge POP services)
Evaluation-as-a-service (standardized harnesses, reproducible runs)
Teleop relay infrastructure (low-latency streaming + compliance logging)
Managed orchestration (workflows across engines/vendors)
This is how you escape fragile BMaaS economics.
9.3 The best “credible big number” isn’t GPU TAM — it’s workflow TAM
Market sizing varies wildly depending on definitions, but the direction is clear: “cloud robotics” is non-trivial and growing. Grand View Research estimates the global cloud robotics market at $7.83B in 2024, projecting $55.68B by 2033.
Treat this as an order-of-magnitude signal (definitions differ across reports), but it supports the idea that robotics cloud spend is big enough for specialization to matter.
10) Risks, reality checks, and what would falsify this thesis
High conviction doesn’t mean pretending there are no counterforces.
10.1 Platform wars and vendor gravity
NVIDIA’s ecosystem is powerful — and it’s natural that many robotics workflows cluster around it. Isaac Sim is positioned as an open-source framework, but licensing is nuanced: the GitHub repository is under Apache 2.0, while building/using may require additional components (Omniverse Kit SDK, assets) under other terms.
A neocloud that bets on a single vendor stack risks becoming a reseller.
Aging-well move: be compatible, not captured.
10.2 The energy and grid constraint is real
Data center power is increasingly a strategic bottleneck, and AI is a major driver. The IEA’s base case projects data center electricity consumption rising to ~945 TWh by 2030.
Robotics workloads are not exempt; sim farms can be power-hungry. Carbon-aware scheduling and power‑aware siting aren’t virtue signals — they’re cost strategy.
10.3 Security and safety are existential
Robotics systems have physical consequences. That raises the bar for:
secure model distribution,
secure logging,
tamper-resistant audit trails,
and safe rollback mechanisms.
Neoclouds that can’t credibly do “secure-by-default” won’t win enterprise robotics.
10.4 What would falsify the neocloud robotics thesis?
Here are the real falsifiers (and how neoclouds hedge):
If robotics companies converge on fully on-prem training + sim because data never leaves secure facilities.
→ Neoclouds pivot to managed private clusters, colo, and edge refinery appliances.If edge autonomy becomes so strong that cloud improvement loops shrink (less central training, more local adaptation).
→ Neoclouds focus on fleet coordination, safety certification pipelines, and evaluation-as-a-service.If simulation tooling consolidates into one vertically integrated platform that bundles infra.
→ Neoclouds must become the best substrate for that platform or the neutral alternative for everyone who doesn’t want lock-in.
The robotics neocloud that wins
A robotics neocloud that wins over the next decade will not be defined by the newest GPU it can buy first. It will be defined by:
Experience Yield as the north-star KPI
A two-tier compute strategy: rack-scale brain training + throughput sim farms
A robot-native data plane that makes thick telemetry economically tractable
Asset Ops that version the world like code (OpenUSD and beyond)
Orchestration, not platform hubris: partner with the best engines and make them run best on your cloud
A credible path through on-prem gravity via hybrid deployment, private connectivity, and edge refineries
Robotics is where “AI infrastructure” stops being about chat and starts being about production. If neoclouds embrace that shift — from GPUs to factories, from tokens to experience — they don’t just survive the next workload transition. They become the infrastructure layer for physical autonomy.
Paid Section: Investor & Neocloud Alpha
Disclaimer: This is not investment advice. It’s an analytical framework + a public-market watchlist for understanding how “robotics workloads” could re-route compute spend across the stack. Do your own work / consult a licensed professional before acting.