
The SpaceX Compute Stack: From Quartz to Orbit (The Blueprint for Builders)
What Musk’s vertical integration exposes about AI’s brutal physical limits, and the tactical blueprint for builders to bypass them.

The market is still analyzing the Musk ecosystem through the wrong lens.
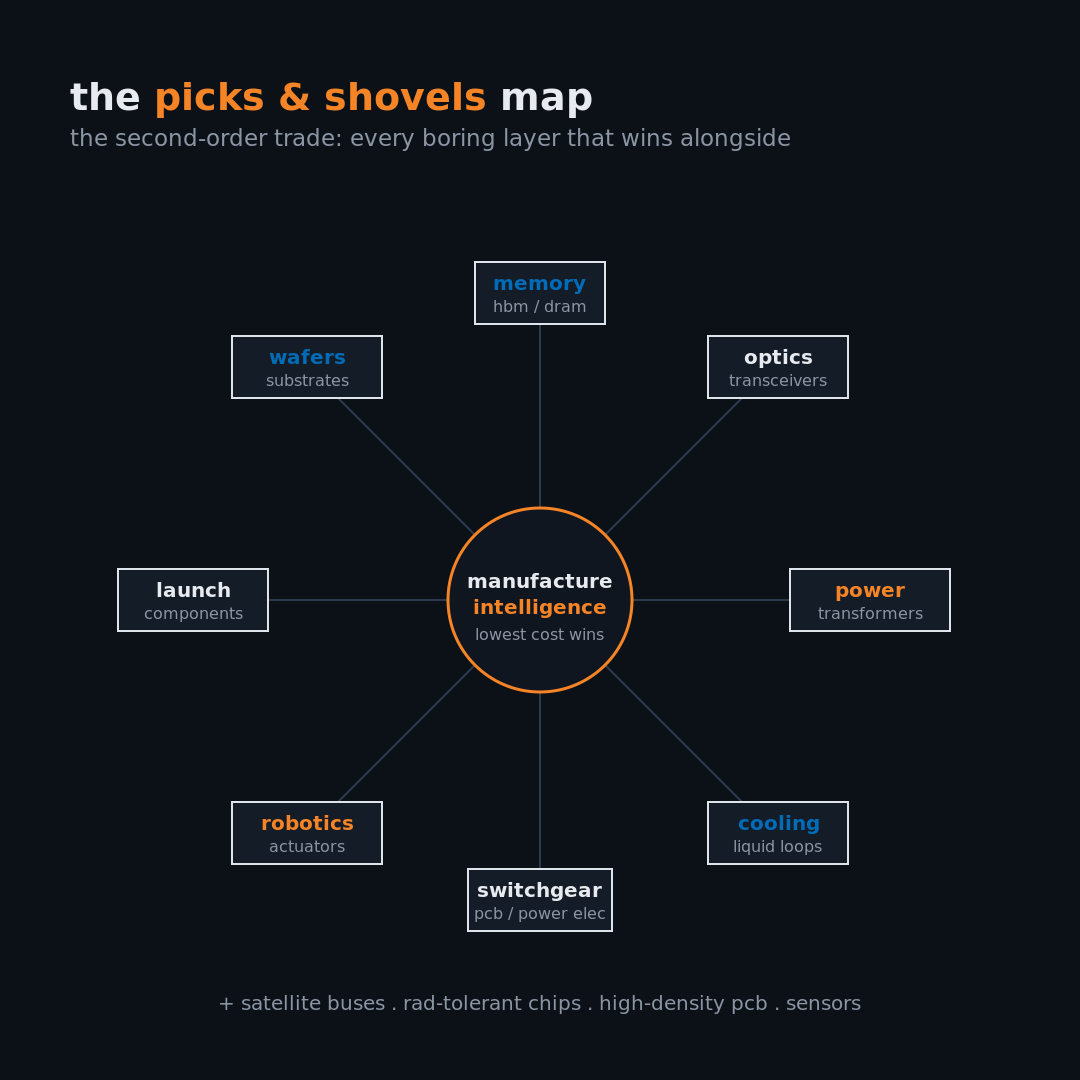
This series is an exhaustive teardown of the physical supply chains powering Space X and Tesla. Why? Because the market is missing the most obvious second-order trade. Even if Musk only gets remotely close to achieving the terawatt-scale infrastructure projects he has in mind, a massive ecosystem of adjacent companies such as wafers, substrates, memory, optics, transformers, switchgear, power electronics, cooling systems, launch components, radiation-tolerant chips, satellite buses, high-density PCBs, liquid cooling, robotics supply chains, and every boring industrial layer nobody wanted to model is going to win alongside them.
The first-order trade is obvious: Tesla, SpaceX, Nvidia, Memory, Optics, and all the bottlenecked infra we have already mapped out over the past year. This trade is already priced in.
The second-order trade is harder and more interesting:
Who sells picks and shovels when AI becomes a physical commodity chain?
That is what we are mapping.
Musk’s goal is simple: to vertically integrate the entire physical stack of intelligence.
Not the model layer.
Not the application layer.
The physical layer.
Energy. Data. Chips. Servers. Packaging. Cooling. Networking. Sensors. Satellites. Launch. Factories. Robots. Cars. Capital.
The next AI monopoly is not the company with the most compute or the fastest tokens. It is the company with the lowest cost to manufacture useful intelligence.
— Fable (RIP)
The first-principles laws behind the Musk Compute Stack
To understand why Musk is building what he is building, start with the physics.
Start with the constraints.
1. You cannot scale exponential compute on a permissioned grid.
AI demand is compounding faster than the power system can respond.
The bottleneck is not energy in the abstract. Earth has energy. The bottleneck is usable AI power: permitted, interconnected, transformed, cooled, financed, and delivered to racks before the offtaker walks.

That is why orbital compute matters. Not because space is easy, but because Earth is slow.
On Earth, power is negotiated.
In Orbit, power is free (its always sunny in space).
Solar area, launch cadence, and radiator mass replace utility queues, zoning boards, water fights, and transformer lead times.
Prediction: Deploying servers will become more optimal in space than on earth by 2028. Scaling in space will be much easier in the long run.
2. A data center is not real estate. It is a thermodynamic machine.
The building is not the asset.
The asset is the envelope: power in, heat out, network connected, hardware utilized, offtake contracted.
AI breaks old data center underwriting because the limiting variable is no longer square footage. It is how densely you can convert electricity into compute while rejecting waste heat.
On Earth, that becomes a water, cooling, HVAC, liquid loop, and local politics problem.
In space, it becomes a radiator problem.

Hard? Yes. Impossible? No. Radiative cooling is physics, not magic. The question becomes radiator area, emissivity, temperature, mass, orientation, shielding, and replacement cycles.
Prediction: Orbital AI creates a new infrastructure metric: useful compute watts per kilogram after thermal rejection.
Not satellite count.
Not launch count.
Watts of usable compute after solar, cooling, radiation, and replacement penalties.
3. Intelligence without embodiment becomes a commodity.
Text and image generation trend toward price compression.
Models spread. APIs commoditize. Open-source catches up. Inference gets competed down.
The harder margin pool is physical.
Moving people.
Moving goods.
Performing labor.
Manipulating matter.
Operating in messy real-world environments.
That is Tesla’s role.
A car is a robot.
A robotaxi is a revenue robot.
Optimus is a labor robot.
Tesla is not just distributing software. It is distributing inference into physical endpoints at scale.
Prediction: Tesla’s long-term moat is not EV manufacturing. It is high-volume embodied inference.
The car was the wedge.
The endpoint is labor.
4. Supply chains are hardware latency.
Every third-party dependency adds delay.
Foundry delay. Packaging delay. Memory delay. Server delay. Networking delay. Transformer delay. Utility delay. Permitting delay.
This is why Terafab matters even if it never beats TSMC.
The goal is not purity. The goal is cycle time.
Terafab is not a full replacement for the semiconductor ecosystem. It is a second door.
One door through Nvidia.
One through Samsung.
One through TSMC.
One through Intel packaging.
One through custom silicon.
One through internal fabs.
Prediction: The winners in AI hardware will be the companies with the most doors into constrained supply.
In AI, resilience is not a corporate slogan. Resilience is deployment speed.
— Also Fable (RIP)
5. Workloads split by the speed of light.
The cloud will not simply move to space.
Latency decides what lives where.
Robot control stays local.
Vehicle safety stays local.
Factory automation stays local.
Real-time physical agents stay near the endpoint.
Power-intensive throughput can move.
Training does not need the same latency profile as emergency braking. Simulations or Synthetic data generation do not care whether they runs in Texas, Memphis, or orbit.
Prediction: AI infrastructure splits into three physical markets:
Training factories optimize for soverign reasons, density, networking, power, and model iteration.
Inference grids optimize for latency, geography, reliability, and cost per task.
Orbital throughput compute optimizes for solar exposure, launch mass, radiator performance, and workload flexibility.
Earth keeps reaction time. Orbit takes scale.
6. Vendors are organizational latency.
If you do not own the physical stack, your deployment speed is capped by the slowest vendor in the chain.
That is the simplest way to understand the Musk strategy.
SpaceX absorbs xAI because training demand should not wait for someone else’s roadmap.
Tesla designs chips because inference volume should not wait for Nvidia.
Terafab exists because chip supply should not wait for external foundry allocation.
Orbital compute exists because power-intensive workloads should not wait for utilities.
Starship matters because orbital AI should not wait for launch scarcity.
Vertical integration is not about saving margin.
Vertical integration is about deleting the queue.
That is the blueprint.
For everyone who is not Musk, the answer is not to copy SpaceX. The answer is to find the queue in your own stack and route around it.
If the bottleneck is power, source delivered megawatts instead of brochure megawatts.
If the bottleneck is hardware, secure servers, GPUs, memory, optics, and networking before the offtake window closes.
If the bottleneck is colocation, match workload density to the right power and cooling envelope.
If the bottleneck is policy, underwrite the jurisdiction before underwriting the site.
If the bottleneck is offtake, turn capacity into a product buyers can actually contract.
That is FPX’s lane.
Musk vertically integrates the bottleneck.
FPX market-integrates it.
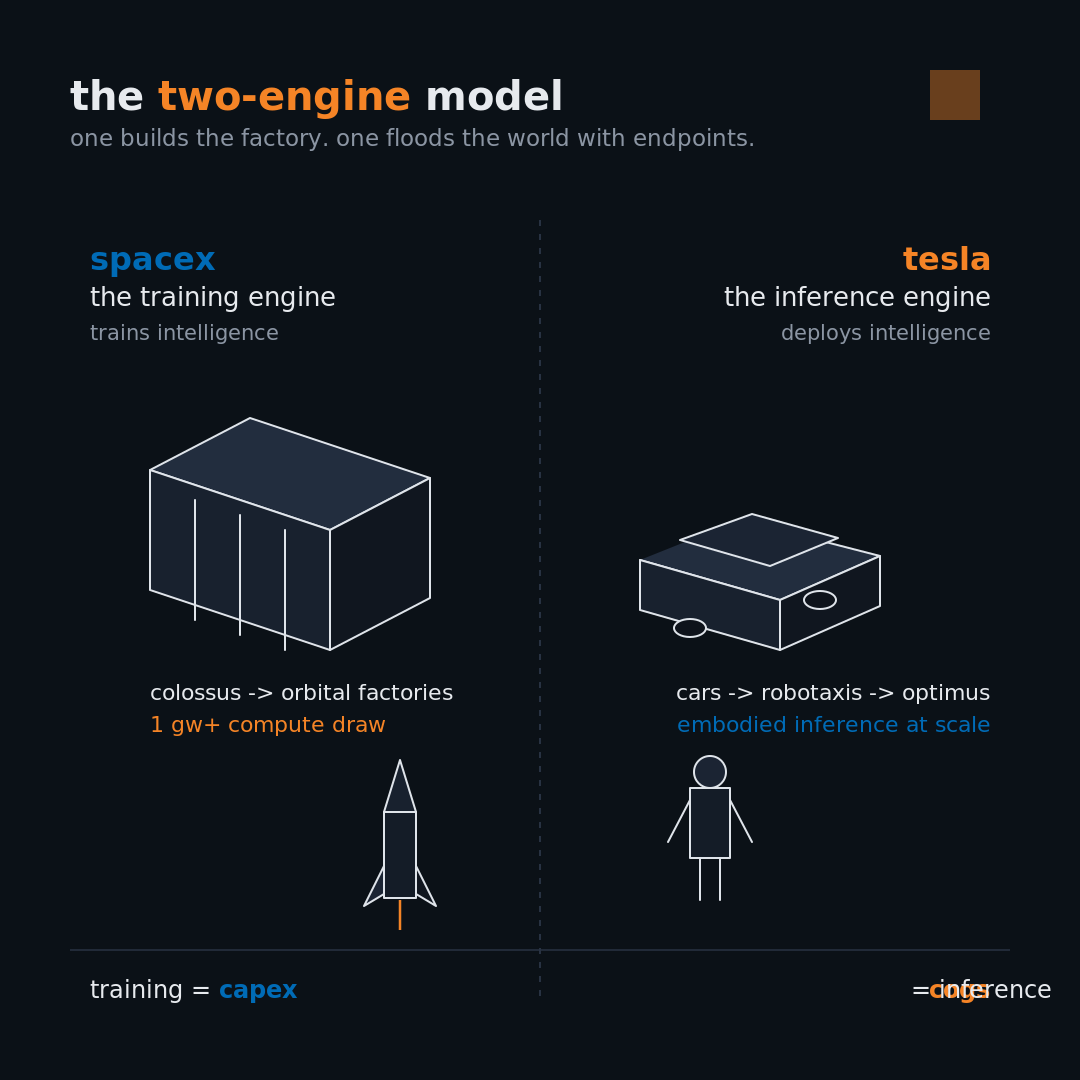
The Two-Engine Model
The Musk Compute Stack is easier to understand if you split it into two engines.
SpaceX trains intelligence.
Tesla deploys intelligence.
One builds the factory.
The other floods the physical world with endpoints.
1. SpaceX is the training engine.
SpaceX’s mandate is not rockets.
It is brute-force infrastructure.
The job is to build the largest AI factories ever attempted, first on Earth, then in orbit.
Colossus is the terrestrial prototype. Not because it is big, but because it was fast. The signal is not GPU count. The signal is deployment velocity.
The AI infrastructure market is full of fake megawatts: land options, utility conversations, future substations, political promises, and renderings of campuses that cannot energize racks.
Colossus is the opposite philosophy.
Industrial shell.
Power.
Cooling.
Networking.
Hardware.
Capital.
Tokens.
Compressed into a deployment cycle that looks more like wartime logistics than real estate development.
That is why SpaceX absorbing xAI matters.
SpaceX did not acquire xAI because Grok needed a better corporate parent. SpaceX acquired the workload. Every infrastructure platform needs anchor demand. xAI supplies the training load. X supplies data and distribution. SpaceX supplies launch, satellites, communications, and the operating system for industrial scale.
Grok is not the endgame.
Grok is the load.
Colossus is the factory.
SpaceX is the infrastructure layer.
When Earth becomes too slow — utility queues, zoning fights, transformer lead times, water politics, interconnect delays, cooling retrofits, copper shortages — SpaceX’s answer is not to wait.
It is to change the battlefield.
That is the orbital data center thesis.
Not because space is easy.
Because Earth is permissioned.
On Earth, power is local, political, and negotiated.
In orbit, power becomes manufactured: solar area, radiator area, launch cadence, satellite production.
The first orbital data center does not need to beat every terrestrial campus. It only needs to prove that power-intensive compute can move from a utility queue to a manufacturing curve.
That is a different bottleneck.
And it is one SpaceX was built to attack.
2. Tesla is the inference engine.
Tesla’s mandate is physical embodiment.
If SpaceX builds the training factory, Tesla builds the endpoints where trained intelligence becomes economically useful.
Cars are the first endpoint.
Robotaxis are the monetized endpoint.
Optimus is the labor endpoint.
The vehicle was never the final form. It was the first mass-produced robot with a battery, sensors, actuators, thermal management, onboard compute, and a customer financing the fleet.
Tesla’s chip roadmap only makes sense through this lens.
AI1 and AI2 were dependency phases: Mobileye first, Nvidia next.
AI3 was the break: Tesla-designed silicon for vehicle inference.
AI4 expanded the envelope.
AI5 and AI6 are the bridge from cars to robots to high-volume physical AI.
The point is not that Tesla wants a better car computer.
The point is that mass inference cannot sit in someone else’s allocation queue.
If Optimus works at even a fraction of the stated ambition, Tesla becomes one of the largest inference-chip consumers on Earth. Cars already make Tesla a high-volume edge-AI platform. Robots turn that demand vertical.
That is why Terafab matters.
Not because Tesla needs to beat TSMC node-for-node.
Because the queue is the bottleneck.
A normal AI company waits. Nvidia allocation. HBM supply. Advanced packaging slots. Server lead times. Switchgear. Utility approvals. Transformers. Permits.
That is not a supply chain.
That is organizational latency pretending to be procurement.
Musk’s answer is always the same: if the queue controls your destiny, delete the queue.
Build around it.
Buy around it.
Or manufacture what the queue was selling you.
Tesla is the inference engine because inference is where AI becomes a recurring physical cost line.
Training is capex.
Inference is COGS.
Every robotaxi mile, every Optimus task, every onboard reasoning loop, every fleet decision turns intelligence into a margin equation.
That is why Tesla is no longer cleanly understood as a car company.
The car is the wedge.
The long-term product is embodied intelligence.
Why This Series Exists
This is a bottleneck map.
The pattern here is simple: when a vendor becomes the bottleneck, Musk internalizes it; when the environment becomes the bottleneck, he changes the environment.
This is not empire-building but is bottleneck migration.
Most builders cannot copy Musk. They cannot launch Starship, build fabs, acquire model companies, or vertically integrate satellites, chips, robots, data centers, and capital.
But they are fighting the same physics:
Power.
Cooling.
Hardware.
Permitting.
Offtake.
Vendor latency.
That is where FPX fits.
Musk is solving AI infrastructure through vertical integration. FPX is solving it through market integration.
We match cloud buyers and AI offtakers with neoclouds that can actually deploy, then help supply the physical stack behind them: colocation, power, servers, GPUs, memory, optics, transceivers, networking, and cooling.
The market does not need more theoretical megawatts.It needs a way to turn demand into live capacity before the offtaker disappears.
The companies that manufacture useful intelligence won't just be defined by their token capital but will also be defined by the infra bottlenecks they crush.
What Comes Next
This piece is about the blueprint.
The rest of the series is about the supply chains.
Part II — Tesla: The Inference Empire
Tesla is not building better cars.
It is building the world’s largest distributed inference network.
We will trace the stack from AI1 to AI7, break down Dojo, Optimus, and Terafab, and map every major supplier positioned to win if embodied AI becomes reality.
The question is simple:
If the future is robots, who supplies the robots?
Part III — Colossus and the AI Factory Doctrine
The most important innovation at xAI was not Grok.
It was deployment speed.
We break down how SpaceX and xAI turned power, GPUs, cooling, optics, networking, and capital into a gigawatt-scale AI factory faster than the rest of the market thought possible.
The future belongs to whoever can manufacture intelligence the fastest.

Part IV — Data Centers in Space
The internet thinks this is science fiction.
We think it is a supply chain problem.
We will make the first-principles case for orbital compute, break down the companies building it, map the supply chain from launch to radiators to space-grade silicon, and identify the winners if power-intensive AI workloads leave Earth.
The biggest AI infrastructure buildout in history may not happen on Earth.
And if Musk is even partially right, the second-order winners will be far larger than the market realizes.