Part 1 : Beyond Power: The AI Memory Bottlenecks Investors Are Missing
This series will map the non‑power bottlenecks—what they are, who controls them, and how to invest around them.

Everyone’s staring at substations and megawatts. Sam Altman flew for memory.
In October 2025 he was in Seoul—not to buy compute—but to pre‑allocate DRAM/HBM from Samsung and SK hynix for OpenAI’s “Stargate” build‑out. South Korean officials talked up 900,000 wafers in 2029; OpenAI framed it as targeting 900,000 DRAM wafer starts per month. Quibble over cadence if you like; the move is the message: the scarce layer sets the pace.
This series maps the non‑power bottlenecks—what they are, who controls them, and how to invest around them. Power caps tell you where a data center can exist. Memory and packaging decide whether those racks do useful work. As GPU fleets scale into the multi‑gigawatt era, the constraint shifts upstream—HBM stacks, CoWoS‑class packaging, ABF substrates, and the flash+disk that feed them
In this first report, we take a ground‑up look at:
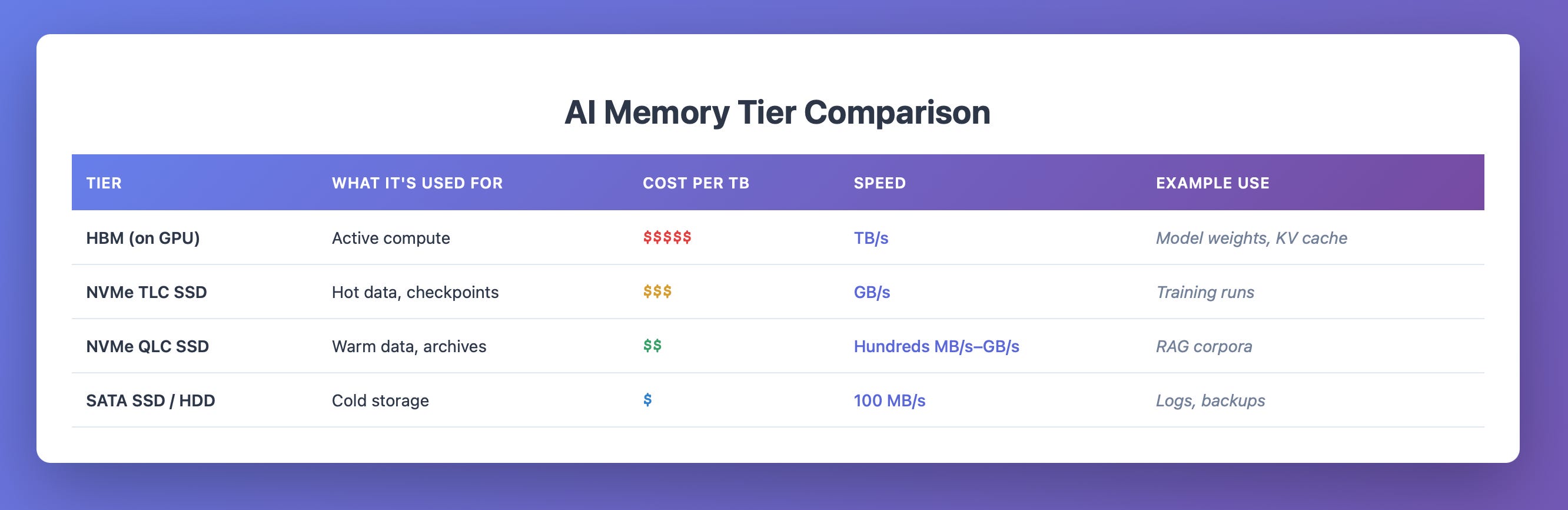
What the three memory tiers actually are—how they differ, and what they do.
How each is manufactured, from raw materials to advanced packaging.
Where the next shortages will emerge as GPU deployments accelerate.
Who stands to win from the widening imbalance between compute and memory capacity.
The Three Tiers of AI Memory
To understand AI memory systems, imagine a busy Restuarant from the Chef’s (GPU’s) perspective
1. HBM — The Chef’s Cutting Board
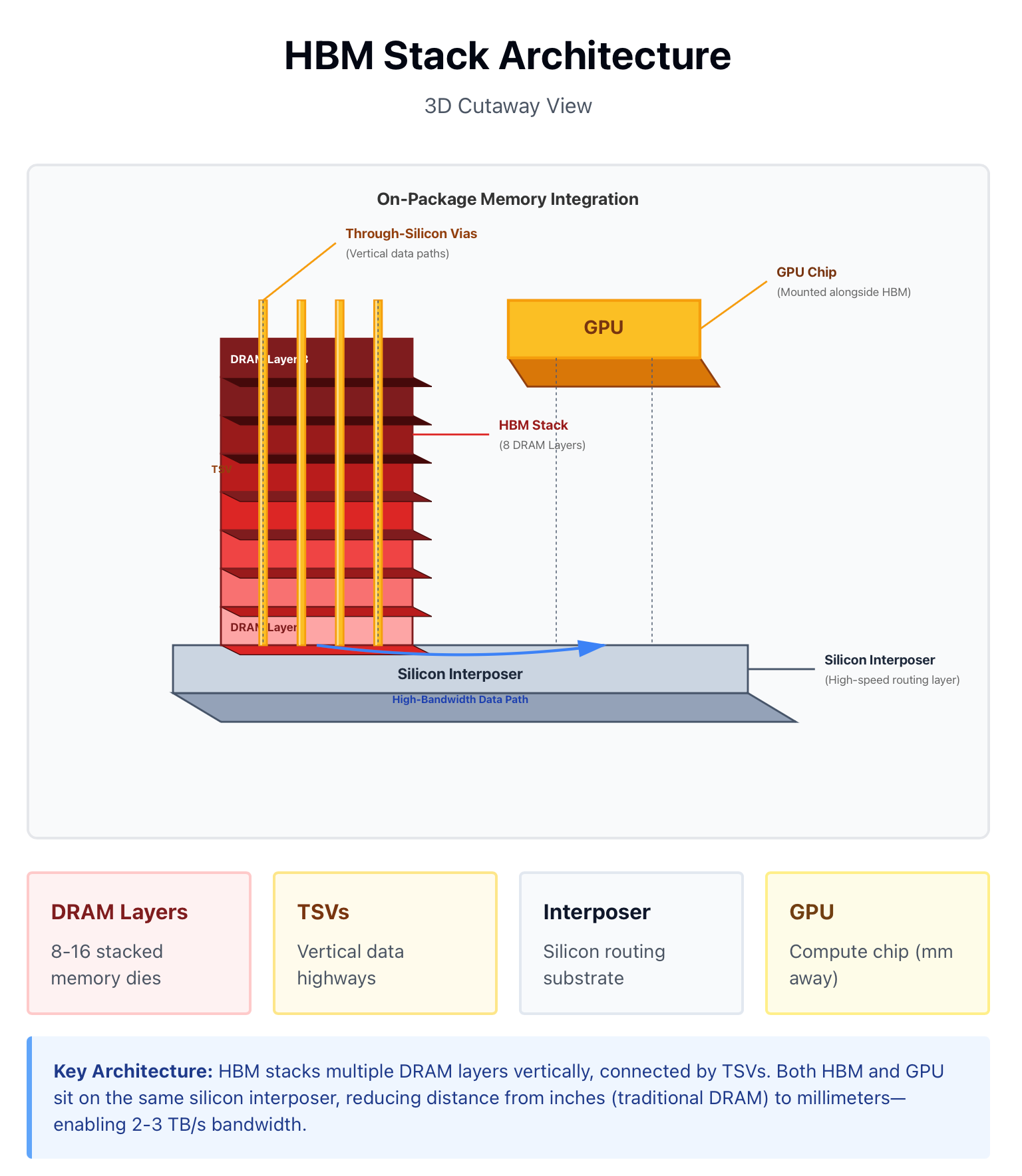
Imagine the chef’s cutting board: it’s where every motion happens—precise, hot, and instantaneous. Space is limited, but every millimeter counts. That’s High-Bandwidth Memory (HBM).
HBM sits directly beside the GPU core, bonded through a silicon interposer using advanced packaging technologies like TSMC’s CoWoS or Samsung’s I-Cube. Each stack is made of multiple DRAM layers vertically linked by through-silicon vias (TSVs)—essentially microscopic elevators for electrons.
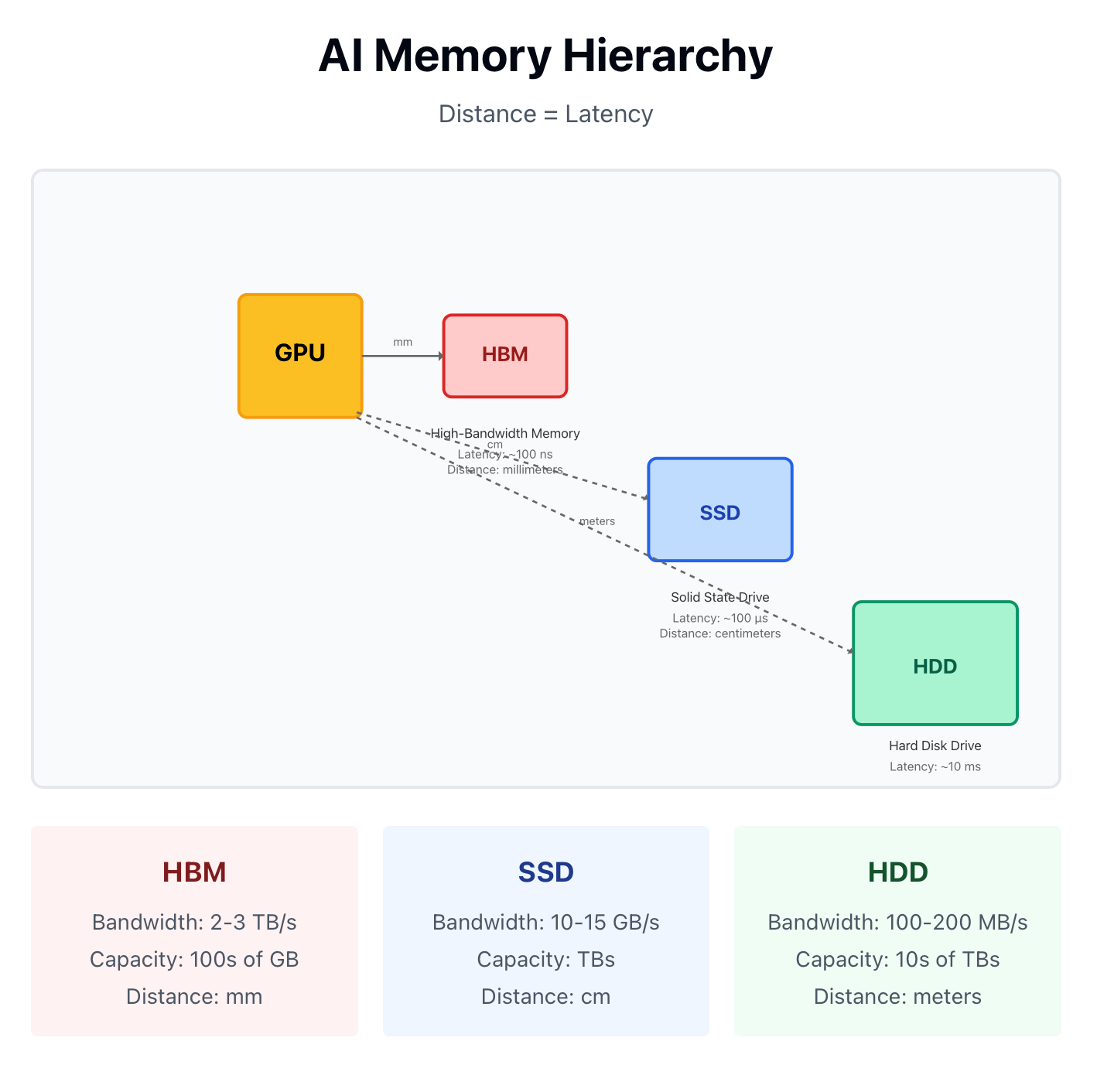
GPUs compute at petaflop scales, but electrons can only move so fast.
The further data travels, the longer the latency.
Traditional DRAM, sitting inches away on a motherboard, becomes the bottleneck.
By moving memory on-package, HBM cuts the distance from inches to millimeters, increasing bandwidth from gigabytes to terabytes per second—the difference between slicing vegetables at the counter versus running to the walk-in fridge every time.
 - Semiconductor Engineering")
But HBM is scarce because:
Capacity is tiny—hundreds of GB per GPU versus terabytes on disks.
Manufacturing is complex—stacks are 3D bonded, yields are low.
Packaging is limited—CoWoS and ABF substrates are in chronic shortage.
This is why HBM is already sold out globally, and why NVIDIA’s delivery schedule is gated not by wafer output, but by how many HBM stacks and CoWoS packages can be assembled each month.
Key suppliers:
Memory: SK hynix, Micron, Samsung
Packaging: TSMC (CoWoS), Amkor (U.S. capacity 2028+), Samsung (I-Cube)
Materials: Ajinomoto (ABF film), Ibiden / Unimicron / Shinko / Nan Ya PCB (substrates)
Investor takeaway: Every incremental GPU shipment consumes HBM stacks, ABF substrates, and CoWoS slots—each a toll booth in the AI supply chain.
2. SSD — The Prep Counter and Fridge
If HBM is the cutting board, SSDs (Solid-State Drives) are the prep counter and refrigerator. They don’t touch the fire, but they make sure the chef never runs out of ingredients mid-service.
SSDs are built from NAND flash memory—non-volatile cells that retain data even when power is off—stacked vertically into hundreds of layers and paired with a controller chip (NVMe) that directs traffic.
Just as a restaurant keeps both quick-access prep bins and deep freezers, AI systems use different kinds of SSDs depending on where the data sits. NVMe drives are the high-speed ones—the prep bins right beside the kitchen—connected over PCIe lanes and able to move data at tens of gigabytes per second. SATA drives are the slower, older kind—the back-room fridge—limited by an interface built for hard drives. And even within NVMe, the flash type changes the economics: TLC SSDs (fast, durable) live inside servers feeding GPUs, while QLC SSDs (denser, cheaper) live outside them, storing the “warm” data that doesn’t change often but must stay nearby. NVMe handles the speed; TLC versus QLC balances performance against cost.

From first principles:
HBM gives speed but almost no persistence. SSDs provide persistence with speed that’s “good enough”—read times measured in microseconds, not nanoseconds, but still orders of magnitude faster than HDDs.
Upstream complexity:
SSDs rely on a deep, global manufacturing chain:
NAND producers: Samsung, SK hynix / Solidigm, Kioxia / Western Digital, Micron
Controller designers: Phison, Silicon Motion, Marvell
Tool makers: Lam Research, Tokyo Electron, Applied Materials
Process gases: NF₃ and WF₆ (from Air Products, Kanto Denka, Merck/EMD)
Investor takeaway: When HBM is constrained, workloads spill into SSD. Every checkpoint, RAG index, and offload increases demand for enterprise NAND and controllers—turning memory shortages into NAND pricing tailwinds.
3. HDD — The Warehouse Out Back
Behind the kitchen lies the warehouse—the Hard-Disk Drive (HDD). It’s not glamorous, but it’s indispensable. Bulk ingredients, cleaning supplies, everything the restaurant relies on for the next week—it all lives there.
In AI, HDDs are the cold, high-capacity tier. They use spinning magnetic platters to store petabytes of data cheaply. Every LLM training run begins with massive datasets—text, code, images—that live here before being pre-processed and staged on SSDs.
From first principles:
HDDs trade speed for capacity. Their latency is measured in milliseconds, but they offer tens of terabytes per drive at the lowest cost per bit.
This cost advantage is crucial: keeping an AI dataset in NAND or HBM would be economically impossible.
An HDD’s supply chain is a masterpiece of specialization:
Platters: glass or aluminum—HOYA dominates glass substrates.
Media: cobalt or FePt magnetic coatings from Resonac / Showa Denko.
Heads & suspensions: engineered by TDK and NHK Spring.
Motors: precision fluid-dynamic bearings by Nidec (~80% global share).
Why it matters:
Every additional trillion tokens of training data or terabytes of user-generated content lands on these disks. As models retrain on fresh data, HDD demand compounds. Tight supply in nearline 30–32 TB drives has already led to longer lead times and firmer pricing.
Investor takeaway: HDDs quietly define the economics of AI storage. When HDD supply tightens, hyperscalers push some cold workloads into QLC SSD tiers, reinforcing NAND cycles and linking all three memory markets together.
Where the Weights Live: Training vs InferenceTraining vs Inference
Training: Raw data sits on HDD with an SSD cache; tokenized shards live on NVMe SSDs to feed GPUs; NVMe also stores frequent checkpoints (weights + optimizer) and acts as a spillover cache during runs.
Inference: Weights execute in HBM (loaded from DRAM/NVMe if not already resident); as context grows the KV cache spills HBM → DRAM → SSD; RAG/vector indexes live on NVMe SSDs for low-latency fetches.
Everything above is the surface view—the “menu” of how AI memory works.
But the real investment edge lies beneath the packaging, inside the factories, chemical plants, and mineral supply lines that feed these components.
In the next section, we peel back every layer: from copper foils and fluorine gases that enable NAND etch processes, to the rare-earth magnets and platinum-group metals behind HDDs, to the ABF films and glass substrates that make HBM packaging even possible.
We’ll map the entire value chain for all three memory tiers—HBM, SSD, and HDD—down to the mineral level, highlighting:
Every chokepoint that could stall AI capacity build-outs,
The companies positioned to capture outsized margins as shortages intensify, and
The signals investors should watch before the broader market catches on.
If you want to understand where the next trillion-dollar wave of AI infrastructure profits will come from, this is where it starts.
The free overview shows what memory does.
The full analysis shows who controls it, where it’s breaking, and how to profit before everyone else notices.